2006年05月31日
零細ソフトウェア作家が収益を得る方法(1)
今日は私のような零細ソフトウェア作家が収益を得る方法について、個人的な想いを色々語ってみたいと思います。
零細ソフトウェア作家いうのは、個人でたいしたことのないソフトウェアを開発し、それを公開している人のことです。
最初に、たいしたことのないソフトウェアで収益を得ることに対する是非についてですが、
たいしたことのないと言っても、そのソフトウェアを使って時間を有効活用している人や、ちょっとした楽しみを得ている人が多少なりともいるのであれば、
その時間や楽しみに対してお金を受け取っても良いのではないかと私は思っています。
でも今の現実の中でどうやって収益を得るか、というのは難しい話です。色々な方法はあると思いますが、これだ!と思える方法はありません。
収益を得るもっとも直接的な方法が、シェアウェアにする、という方法です。
優秀なソフトウェアでしたら、この方法で立派に収益を得られると思います。しかし、残念ながら、たいしたことのないソフトウェアではほとんど収益が得られません。
ユーザはそのソフトウェアを使わず、たんに他のフリーソフトを使うだけだからです。正直、1万円得られたらたいしたものでしょうね。
その上、シェアウェアにしたらユーザ数はなかなか増えないでしょう。大勢に使ってもらえないと私は幸せになりません。
シェアウェアにする、という方法の派生方法の一つとして、フル機能版をシェアウェアとして公開し、機能限定版をフリーソフトとして公開する、という方法があります。
でも私はユーザには私がベストだと思う構成、つまりフル機能版を使って欲しいのです。フル機能版を使ってもらえないと私は幸せになりません。
機能限定版を出すのはあまり好きではないです。それ以前にたいしたことのないソフトウェアをさらに機能限定しちゃったら誰が使うんでしょうね。
カンパウェアにする、という方法もあります。
お金を払わなくても機能制限はないけれど、気に入った人にはお金を払ってもらう、という方法です。
私は、この方法は、お金を払ったユーザになんらメリットがないのでちょっと気に入りません。お金を払ったらユーザは幸せになるべきだと思います。
広告を表示する、という方法もあります。
昔の東風荘やOpera無料版がこの方法を使っていたと思います(今は分かりません)。Jwordをバンドルするのもこの方法の一種ですね。
しかし、ユーザが広告を鬱陶しいと感じたらユーザは幸せになりません。広告がユーザの使い勝手を妨げているかと思うと私も幸せになりません。
デフォルトで広告OFFにできるのでしたら使っても良いのではないかと思いますけどね。
どこかの企業に売り飛ばす、という方法もあります。
これは金額は結構行くはずです。うまく行けば数百万単位になるかもしれませんね。元が取れるところまで行くかも知れません。
しかし、売ってしまうとあれこれとややこしい権利問題が発生する可能性があります。下手をすると今後自力で開発を継続することができなくなるかもしれません。これでは私は幸せになりません。
もっとも、それ以前に、たいしたことのないソフトウェアを買う企業はないでしょうが。
というわけで、私が良さそうと思う方法は今のところはないようです。
なんというか、私がとユーザが幸せになる方法が欲しいのですが、ないものですね。
なければ作ってしまえ!と言いたいところですが、残念ながら作れるほどの力はありません。
でもアイデアだけはあるので、それを説明したいと思います。
というところで以下次回。
2006年05月30日
WinHTTPのサンプルコード
5/29の記事の続きです。
- 環境
- Visual C++.NET 2003
- OS
- WindowsNT+IE5.01 又は Windows2000以降
WinHTTPは、レスポンスのヘッダに関する細かい処理を行うことができます(HTTPライブラリとしては当たり前ですが)。
そこで細かい処理を行う例として、ステータスコードが301の場合だけリダイレクト先のURLを記録し、それ以外の場合はリダイレクト先のURLを記録せずに転送するコードを書いてみました。
オプション設定でリダイレクトをOFFにしておかないとWinHTTP内部で転送処理が行われてしまうので気をつけましょう。
#include <windows.h>
#include <string>
#include <iostream>
#import "winhttp.dll" named_guids
int main(void)
{
::CoInitialize(NULL);
std::string Uri = "http://www.sutosoft.com/test/redirect/301.html";
std::string Moved;
WinHttp::IWinHttpRequestPtr Request;
Request.CreateInstance(WinHttp::CLSID_WinHttpRequest);
Request->Option[WinHttp::WinHttpRequestOption_EnableRedirects] = false;
for (int i = 0; i < 10; ++i) {
Request->Open("GET", Uri.c_str());
Request->Send();
long Status = Request->Status;
if (Status == 301 || Status == 302 || Status == 303 || Status == 307) {
Uri = Request->GetResponseHeader("Location");
if (Status == 301) {
Moved = Uri;
}
}else {
break;
}
}
if (!Moved.empty()) {
std::cout << "Moved Permanently. New URI = " << Moved;
}
std::cout << Request->ResponseText;
::CoUninitialize();
};
リダイレクト回数は最大10回にしました。
Option[WinHttp::WinHttpRequestOption_MaxAutomaticRedirects]のデフォルト値が10なので、それに合わせた形です。
なお、WinHTTPは、同じURLにリダイレクトするようなリダイレクトループを検出できるようです。
以下のURLはリダイレクトループテスト用のURLですが、
http://www.sutosoft.com/test/redirect/301_loop.html
WinHTTPでこのURLにアクセスすると、リダイレクト許可オプション(Option[WinHttp::WinHttpRequestOption_EnableRedirects])に関わらず、リダイレクトを行わないで終了するようです。
WinInetだと、永遠にリダイレクトし続けます。例えば上記リダイレクトループテスト用のURLにInternet Explorer 6SP2でアクセスすると終了しません。
WinHTTPはちゃんと進歩してますね。
2006年05月29日
WinHTTPの紹介
- 開発環境
- Visual C++.NET 2003
- OS
- WindowsNT+IE5.01 又は Windows2000以降
WindowsのHTTPライブラリであるWinHTTPを紹介します。
このライブラリはWinInetに代わる新しいHTTPライブラリです。
このライブラリを使うことにより、以下のようなコードだけでURLからデータを取得できます。
とても簡単です。WinInetよりも簡単でしょう。
#include <windows.h>
#include <iostream>
#import "winhttp.dll" named_guids
int main(void)
{
::CoInitialize(NULL);
WinHttp::IWinHttpRequestPtr Request;
Request.CreateInstance(WinHttp::CLSID_WinHttpRequest);
Request->Open(L"GET", L"http://www.sutosoft.com/");
Request->Send();
std::cout << Request->ResponseText;
::CoUninitialize();
return 0;
};
IWinHttpRequestインターフェースの詳細については、「IWinHttpRequest」を参照して下さい。
なお、WinHTTPは、WindowsNT + IE5.01か、Windows2000以降が必要です。Windows95やWindows98では動作しません。
また、プロキシ設定のためのツールも用意されています。詳しくはMicroSoft 技術情報の「ServerXMLHTTP が動作するにはプロキシ構成ユーティリティを使用する」を参照して下さい。
2006年05月26日
Heimdallrのホントのバグ対策その6
5/24の記事の続きです。
今までWinInetのバグ対策について検討してきました。 一応、WinInet以外のHTTPライブラリを使うという手もあります。これについても検討しておきましょう。
WinInet以外のHTTPライブラリを列挙してみます。
(1) XMLHTTP
(2) WinHTTP
(3) ServerXMLHTTP
(4) 自作
ほとんどMicrosoft製ですね・・・。
(1)XMLHTTPですが、「ServerXMLHTTP に関してよく寄せられる質問 (FAQ)」によると、 どうやらWinInetをベースにしているようです。ということは、同じバグがあると思われます(確かめてはいませんが)。 よって、これを使っても問題は解決しないため、検討対象から除外します。
(2)WinHTTP (3)ServerXMLHTTPは、先ほどのページによると
ServerXMLHTTPはWinHTTPをベースにしているようです。ということはWinHTTPだけ検討すれば十分ですね。ServerXMLHTTPは検討対象から除外します。
WinHTTPは「WinHTTP - ユーティリティの紹介と Windows Vista での改善」でも紹介されていますが、
WinInetの代替となる新しいHTTPスタックということなので、これを使えばWinInetのバグは解決しそうです。素晴らしいですね。
しかし課題が2点。1点目は、Win98SEではWinHTTPを使えないということです。Heimdallrは、今まで労力をかけてWin98SEをサポートしてきました。
それをここで失ってしまうのはもったいないです。2点目の課題はプロキシ設定です。WinHTTPは、Internet Explorerのプロキシ設定とは
まったく別のプロキシ設定で動きます。
1点目の課題は、Win98SEはWinInetを使い、Win2000以降だけでWinHTTPを使うという手で解決できます。
しかし、2点目の課題が厳しすぎます。Internet Explorerのプロキシ設定は複雑であり、簡単に設定をコピーできません。
もしもHeimdallrがWinHTTPを採用すれば、プロキシ設定でトラブルが起きて大勢のユーザが困るでしょう。私はこういうことを望みません。
既存のユーザが居ない新しくアプリケーションを作るのでしたら、WinHTTPを使うんですけどね。
(4)自作についても同じことが言えます。プロキシ設定周りでトラブルが発生するでしょう。ついでに自作ではHTTPSをサポートできません。
というわけで、WinInet以外を使うと、ユーザはトラブルに悩まされそうな感じです。 というわけで、HeimdallrはWinInetと心中するべきだと思っております。やれやれ。
でも次にアプリケーションを作る機会があれば、WinHTTPを使いますよ!
もうWinInetはこりごりです。
2006年05月24日
Heimdallrのホントのバグ対策その5
5/23の記事の続きです。
今までバグ対策であるInternet Explorerの設定変更について色々と検討してきました。 対策をこれと決めてしまう前に、一応、他に何かないか検討しておきましょう。
バグ発生条件は、WinInetのバグ情報のページによると、次のようになっています。
This only happens when the server uses chunked encoding and abruptly closes a connection.
Transfer-Encodingがchunkedで、かつ突然コネクションが切断されたときに発生するわけです。
突然コネクションが切断というトリガの詳細がよく分かりませんが、HeimdallrはタイムアウトするとInternetCloseHandleを呼び出してコネクションを切断するので、これがトリガとなっている可能性があります。
ということはこんな対策が考えられます。
Transfer-Encodingがchunkedの場合、タイムアウトするまでの時間を長くする、あるいはタイムアウトしない。
完璧な対策ではありません。別の要因によりコネクションが切断された場合は不具合が発生する恐れがありますし、サーバとの通信速度が低速の場合はダウンロード時間が延びます。 ですが、不具合発生確率を下げることはできそうです。Internet Explorerの設定を変更する必要もありません。なんとなく良さそうですね。うーん。
2006年05月23日
Heimdallrのホントのバグ対策その4
5/22の記事の続きです。
バグ対策のためにHTTP 1.0を使うようInternet Explorerの設定を変更しても、大丈夫そう(ホントか?)なことが分かってきました。 次はInternet Explorerの設定を変更する方法について検討しましょう。
具体的な設定変更方法を挙げます。
(1) 設定を手動で変更するようドキュメントに書く
(2) (1) + 設定が変更されていない場合は起動時に警告メッセージを出す。
(3) レジストリを書き換えて自動的に変更してしまう(レジストリ変更方法)
(4) (3) + 書き換え時に警告メッセージを出す。
このバグにより、Heimdallrを普通に使っている方でもハングする可能性があります。ハングというのはHeimdallrのような常駐ソフトにとっては致命的な不具合です。
ですので、Heimdallr使用者全員にInternet Explorerの設定を変更してもらえるよう工夫する必要があります。
そうなると、(1)はちょっと苦しいですね。
また、(2)(4)の警告メッセージですが、メッセージの内容が問題です。Heimdallr使用者のうちHTTP 1.0と1.1の違いを分かる方はほとんどいませんし、ましてやHTTP 1.0を使うことによりどのようなことが起こるか分かる方はまずいないでしょう。私も分かりません。そうなると、どんな文面にすれば良いんでしょうね。「HTTP 1.1を使用するとHeimdallrがハングする恐れがあります。HTTP 1.0を使用するようInternet Explorerの設定を変更しても宜しいでしょうか?」かな。いやいやいや。そもそもHTTP 1.1とか1.0という単語を使ってはいけないのです。メッセージを表示するからには、大半のユーザに理解できるメッセージでなければなりません。これではだめです。 正直、私には適切なメッセージが思いつきません。
適切なメッセージがないのでしたら、そもそもメッセージを表示しないで処理しなければなりません。ユーザに理解できないメッセージを出して何かを促すよりは、何も出さない方が良いのです。 そうなると選択肢は(3)しかありません。
というわけで(1)~(4)の中から選ぶとしたら(3)です。
でも今すぐ(3)の対策をしてリリースしよう!とまで思えないのは、やっぱりInternet Explorerの設定、それもインターネットアクセスの根幹に関わる設定を変更することが、どのような影響をもたらすのか分からないからです。うーん。どうしようかなぁ・・・。
2006年05月22日
Heimdallrのホントのバグ対策その3
5/20の記事の続きです。
このバグの対策を行うためには、Internet Explorerの詳細設定を変更することが必要だと分かりました。
お次は副作用について検討してみましょう。 このバグの対策により、他のWinINetを使用しているほぼ全てのアプリケーションがHTTP 1.1からHTTP 1.0へ移行することになるわけです。さて、どんな不具合が発生する可能性があるでしょうか。
これはさすがに分かりません。世の中WinINet使っているアプリケーションは山ほどありますし、HTTPサーバも山ほどありますので、全部検討するのはどうみても無理です。
そこで肝心のHeimdallrに悪影響がないことだけでも確認しておくことにしました。 でもHeimdallrの挙動はサーバ側の動作によって変わるので、ある程度サーバを絞り込む必要があります。 今回は、Feed Meterのブログランキングを利用してサーバを絞り込み、確認OK判断を次のように行うことにしました。
Feed Meterのブログランキング100位までに登録されているRSS FeedのURLを全てHeimdallrに登録し、HTTP 1.0とHTTP 1.1でHTTPリクエスト送信の際のリクエストヘッダとレスポンスヘッダを 取得し、HTTPバージョンの違いによるヘッダの差異を目視確認して、問題なければOKとする。
リクエストヘッダの違い
HTTP 1.0のリクエストはこうでした。
GET /xxx.rdf HTTP/1.0 User-Agent: Heimdallr 1.11alpha2 Accept-Encoding: gzip Host: www.example.com Pragma: no-cache
HTTP 1.1のリクエストはこうでした。
GET /xxx.rdf HTTP/1.1 User-Agent: Heimdallr 1.11alpha2 Accept-Encoding: gzip Host: www.example.com Cache-Control: no-cache
キャッシュに関するフィールドがあるのは、HttpOpenRequestのフラグにINTERNET_FLAG_RELOADを指定したからでしょう。
HostフィールドはWinINetが勝手に付与したフィールドです。このHostフィールドはHTTP 1.1じゃないと使えないと思うのですが、HTTP 1.0でも平気で使ってます。
また、Accept-Encodingフィールドも、HTTP 1.0では"x-gzip"の方が良さそうです。
レスポンスヘッダの違い
肝心のレスポンスヘッダですが、結果としては問題はまったくありませんでした。
ステータスコードは全て一致していました。
フィールドの違いは若干ありましたが、意味のありそうな違いはありませんでした。
一応気が付いた点を列挙しておきます。
HTTP 1.0使用時にTransfer-Encodingフィールドを付けるサーバはありませんでした。これがあったらバグが再現してしまうので無くてなによりです。
HTTP 1.0使用時にConnection: closeを付けるサーバがありました。あまり意味はないと思うんですが・・・。
HTTP 1.0使用時にX-Pad: avoid browser bugを付けるサーバがありました。古いブラウザのバグ避け用であまり意味はないはずです。
HTTP 1.1使用時にAccept-Encoding: gzipを付けるサーバは、HTTP 1.0使用時でも付けていました。
結論
結局具体的な問題はありませんでした。一番心配だったのはHTTP 1.0にはVirtualHost機能がないことだったのですが、HTTP 1.0でもWinINetは平気でHostフィールドを付けるし、サーバも平気でHostフィールドを処理するので問題がなさそうです。
なお、これは2006/05/17の時点でFeed Meterのブログランキングのトップ100に登録されているサーバについてだけのお話です。世の中でどれくらい通用するのかは分かりません。ですが、これを見た限りでは、HTTP 1.1の替わりにHTTP 1.0を使っても具体的な問題は無さそうです(仕様上の問題はたくさんありそうですが)。
ところで、この検討を行って感じたのですが、世の中のWebサーバ(今回確認したサーバは90%がApacheでしたが)は、あまりHTTPバージョンに拘らず、具体的な問題が発生しないよううまくHTTPリクエストを捌きますね。 きっと、過去、HTTPのバージョンが上がったときに発生した色々な互換性問題をクリアしていって今のような実装になったのでしょう。なんとなく歴史を感じました。
2006年05月21日
猫喫茶の女王猫
本日は猫喫茶に行ってきました。
空いている時間を狙ったので人は居ませんでしたが、猫はみんな寝てました。残念。
とりあえず起きていた女王猫の写真を取ってきました。


表情が良く変わる猫ですね。
猫はみんなそうかもしれませんが。
2006年05月20日
Heimdallrのホントのバグ対策その2
5/19の記事の続きです。
このバグの対策としてMicrosoftが提示しているのは、以下の2点を行うことです。
(1) HttpOpenRequestの第4引数を"HTTP/1.0" とする。
(2) Internet Explorerの詳細設定の「HTTP 1.1 を使用する」をOFFにする。
HTTP 1.0を使うだけなのになんでInternet Explorerの詳細設定を変更する必要があるんでしょうね。
ちょっと疑問に思ったので、これらの設定を変更した結果、リクエストヘッダのバージョンがどうなるのか調べてみました。
| HttpOpenRequestの第4引数 | 詳細設定の「HTTP 1.1を使用する」 | リクエストヘッダのバージョン |
| NULL | ON | HTTP/1.1 |
| NULL | OFF | HTTP/1.0 |
| "HTTP/1.0" | ON | HTTP/1.1 |
| "HTTP/1.0" | OFF | HTTP/1.0 |
| "HTTP/1.1" | ON | HTTP/1.1 |
| "HTTP/1.1" | OFF | HTTP/1.1 |
(1)の実施は必須ではなく、HttpOpenRequestの第4引数はNULLでも良いようですが、残念ながら、(2)の実施は必須のようです。(2)を実施しないと、HTTP 1.0を使うことはできません。HttpOpenRequestの第4引数がどうあれ、強制的にHTTP 1.1になってしまうようです。うーん。
2006年05月19日
Heimdallrのホントのバグ対策その1
5/17の記事の続きです。
WinINetを使用してインターネットアクセス中にCPU使用率が100%になってハングしてしまうという不具合の原因は、
t.oさんに指摘してもらったWinINetのバグだと思われます。
やっと辿りつきました。t.oさん本当にありがとうございました。
「WinINet 100% CPU」で検索すればすぐに見つかったんですね。だいぶ遠回りしてしまいました。
今回の教訓は「たまにはOSのバグも疑ってみよう」です。
さて原因が分かった所で対策です。
WinINetのバグ情報のページに対策が書いてあります。
「HTTP 1.0を使え」ということだそうです。・・・。えーそれでいいの?
デフォルトではHTTP 1.1なのですから、HTTP 1.0を使うことにより何か問題は発生しないんですかね。ちょっと慎重に調べる必要があります。
2006年05月18日
Google Calendar Data APIのgsessionid
Google Calendar Data APIを使ってカレンダーのイベントFeedを取得するためには、gsessionidと呼ばれるIDが必要です。 gsessionidは、カレンダー取得用のURLにGETリクエストを送ることで簡単に取得できます。
例えば、こんな感じのGETリクエストを送信すると、
GET /calendar/feeds/tfggtnbkkq7jp5tfggrsm3kld0@group.calendar.google.com/public/full HTTP/1.1 Host: www.google.com
以下のようなレスポンスが返ってきます。
HTTP/1.1 302 Moved Temporarily Set-Cookie: S=calendar=8ctwctPlkp4 Location: http://www.google.com/calendar/feeds/tfggtnbkkq7jp5tfggrsm3kld0@group.calendar.google.com/public/full?gsessionid=8ctwctPlkp4 Content-Length: 0 Content-Type: text/html
「8ctwctPlkp4」がgsessionidです。Set-Cookieフィールドから取り出すこともできそうですが、公式な手順はLocationフィールドのURLから取り出すことなのでそうしましょう。
こうして取得したgsessionidは、イベントFeedを取得するために使います。
例えば、以下のようにURLにgsessionidを含めたGETリクエストを送信すると、
GET /calendar/feeds/tfggtnbkkq7jp5tfggrsm3kld0@group.calendar.google.com/public/full?gsessionid=8ctwctPlkp4 HTTP/1.1 Host: www.google.com
以下のようなレスポンスが返ってきます。
HTTP/1.1 200 OK Content-Type: application/atom+xml; charset=UTF-8 Content-Length: 5509
レスポンスボディはイベントFeedです。このようにしてgsessionidを使うことによりイベントFeedを取得することができます。
これでgsessionidの取得方法と使い方は分かりました。しかし、そもそもこのIDは一体何のためにあるのでしょうか?
認証のため?でもgsessionidを取得するのにパスワードも何も要りません。それじゃ認証の役には立たないでしょう。
パフォーマンスを上げるため?gsessionid取得時にGoogleがデータの先読みをしておくとか・・・。でもgsessionidは結構使いまわしができます。例えば一つのgsessionidで複数のカレンダーにアクセスすることができます。これでは先読みは難しそうです。gsessionidを生成して302を返すだけでもそれなりにコストがかかるはずなのでパフォーマンスはかえって悪くなるでしょう。
では一体何のためか・・・と考えていたところ、Google Calendar Data APIのドキュメントにちゃんと書いてありました。
「That gsessionid parameter is the way that Calendar keeps track of your session, to improve speed of response.」
だそうです。gsessionidはアプリケーションの振る舞いをサーバ側から観測するための仕組みのようですね。
でもってGoogleはそうした観測に基づいてGoogle Calendarを改良していくようです。なんとも素晴らしい。
この手のWebサービスのAPIに、Webサービスの改良を目的とした仕組みが入っているものは珍しいですね。私は他に見たことがありません。 良いWebサービスに仕立て上げるぞ!という強い意志を感じた気がしました。なんというかGoogleらしいですね。
2006年05月17日
Heimdallrのバグ対策
5/16の記事の続きです。
不具合の原因は恐らく以下の通りです。残念ながら、断言できるところまで解析はできませんでしたが。
Heimdallrは、MFCのCInternetSession/CHttpConnection/CHttpFileクラス(以下、CInternetSession関連クラス)をマルチスレッドで使用してインターネットアクセスを行っておりますが、
残念ながらこれらのクラスはスレッドセーフではないことが原因のようです。
特に、Heimdallrでは、サーバに接続した後、一定時間が経過した場合、別スレッドからCHttpFile::Closeを呼んで切断しているのですが、このやり方に問題があったようです。
さて不具合の原因が大体明らかになったところで、対策を考えてみます。
スレッドセーフじゃないならスレッドセーフにすれば良いだけのようですが、残念ながらそう簡単にスレッドセーフにはできないようです。
まず最初に、Heimdallrのインターネットアクセスに関する要件をまとめてみます。
(1) HTTPに対応していること。
(2) HTTPSに対応していること。
(3) 同時に複数の接続が張れること。
(4) 指定した時間が経過した場合は強制的に接続を切断できること。
従来は、(1)(2)を満たすためにCInternetSession関連クラスを使い、(3)(4)を満たすためにマルチスレッドを使っていたわけです。
不具合の対策を行った後も、これらの要件を全て満たす必要があります。
といっても(1)(3)は別にどうということはありません。厄介なのは(2)(4)です。
とりあえず対策を適当に挙げてみます。
(a) CInternetSession関連クラスのラッパを作成してスレッドセーフにする。
(b) (4)を実行するときに別スレッドからCHttpFile::Closeを呼ぶ方法以外の方法を使う。
(c) 自分でsocketを使ってスレッドセーフなHTTPライブラリを作る。
(d) スレッドセーフなWinINetライブラリのラッパクラスを作成する。
(e) 他のHTTPライブラリを使用する。
対策(a)について。残念ながら(4)を満たしつつスレッドセーフにする方法が分かりませんでした。WinINetの非同期モードを使えればなんとかなりそうなのですが、CInternetSession関連クラスは同期モードにしか対応していないようなので無理そうです。
対策(b)について。CInternetSessionクラスは受信タイムアウトを設定できるのでなんとなく行けそうだったのですが、残念ながらこの受信タイムアウトは受信パケット間のタイムアウトを指定するパラメータでした。つまり、タイムアウトを2秒に設定しておいても、1秒毎に1バイト受信し続けることができれば何秒経ってもタイムアウトしないのです。これでは(4)を満たせません。残念。
対策(c)について。これは(2)が無理。勘弁して下さい。
対策(d)について。これは対策(a)(b)を同時に実施するのに近いものがあります。WinINetの非同期モードが使えるラッパクラスにすれば全ての要件を満たせそうです。
対策(e)について。(2)(4)を同時に満たせるライブラリが見つかってみません。まあ(d)で行けそうだからあまり探してもいないんですけど。
というわけで現状は対策(d)を進める予定です。
2006年05月16日
Heimdallrのバグ解析の続きの続き
5/12の記事の続きです。
先日またHeimdallrの例の不具合が起きたので解析を進めました。
残念ながらまだ原因は確定はできませんでしたが、インターネットアクセス用スレッド処理がスレッドセーフになっていないのにマルチスレッドを使っているのが原因でしょう。
今回の件で思い知りましたが、マルチスレッドアプリケーションのデバッグって大変ですね。不具合が起きても原因がなかなか分かりません。
各スレッドの状況が手に取るように分かるデバッガが欲しいですね・・・。
(Winnyの技術に書いてありましたが)Winny開発者が、マルチスレッドを使わないでWinnyを設計した気持ちが良く分かります。
私も今後はマルチスレッドを使いません、と言いたい所ですが、CPUのトレンドはマルチコア。つまりマルチスレッドに向いているのです。
何時までも避けていられるものではないでしょう。
むしろ、マルチスレッドアプリケーションをまともに設計できるようになるために、今のうちにマルチスレッドの落とし穴に嵌りまくっておいたほうが良さそうですね。
というわけで、これに懲りずに今後も積極的にマルチスレッドを使って行こうかと思っています。
でも辛いなぁ・・・。
2006年05月14日
Shift_JISとUnicodeの変換用関数
- 環境
- Visual C++.NET 2003
Windows上でShift_JISのようなマルチバイト文字とUnicodeとの変換を行う関数を紹介します。
これはMFCやATLが使えない場合の関数です(例えばVisual C++ 2005 Express Edition使用時のように)。
MFCが使えればCStringを使うべきですし、ATLを使えばCW2AやCA2Wを使うべきでしょう。
まずはUnicodeからマルチバイト文字への変換関数です。
std::string UnicodeToMultiByte(const std::wstring& Source, UINT CodePage = CP_ACP, DWORD Flags = 0);
std::string UnicodeToMultiByte(const std::wstring& Source, UINT CodePage, DWORD Flags)
{
if (int Len = ::WideCharToMultiByte(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), NULL, 0, NULL, NULL)) {
std::vector<char> Dest(Len);
if (Len = ::WideCharToMultiByte(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), &Dest[0], static_cast<int>(Dest.size()), NULL, NULL)) {
return std::string(Dest.begin(), Dest.begin() + Len);
}
}
return "";
}
でもってこれがマルチバイト文字からUnicodeへの変換用関数です。
std::wstring MultiByteToUnicode(const std::string& Source, UINT CodePage = CP_ACP, DWORD Flags = 0);
std::wstring MultiByteToUnicode(const std::string& Source, UINT CodePage, DWORD Flags)
{
if (int Len = ::MultiByteToWideChar(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), NULL, 0)) {
std::vector<wchar_t> Dest(Len);
if (Len = ::MultiByteToWideChar(CodePage, 0, Source.c_str(), static_cast<int>(Source.size()), &Dest[0], static_cast<int>(Dest.size()))) {
return std::wstring(Dest.begin(), Dest.begin() + Len);
}
}
return L"";
}
しかしこういう定型処理を行う関数は自前で作るものじゃないですね。boostにはないんですかねぇ・・・。
(2008/02/12追記)上記変換関数のバージョンアップ版を作成しました。
2006年05月13日
Google Trends
Google Trendsが面白いです。最近Google元気ですね。
とりあえずペット対決!
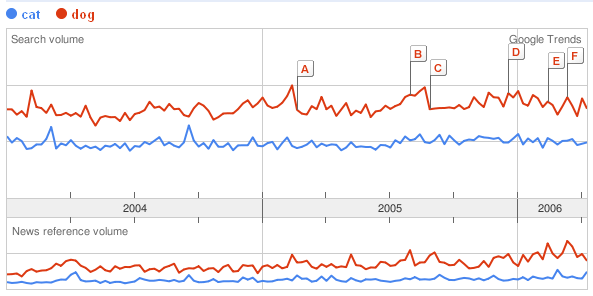
あわわわわわ。負けてますよ。どうしましょう。
お次は検索エンジン対決!
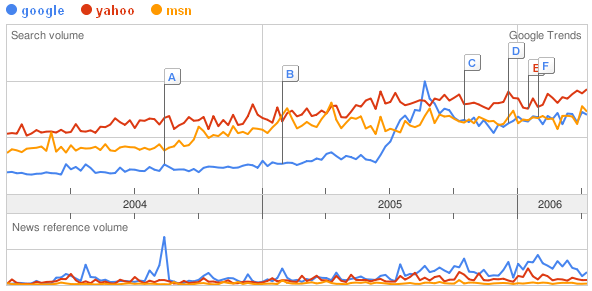
Google負けてますよ!頑張れ!
2006年05月12日
Heimdallrのバグ解析の続き
5/3の記事「Heimdallrのバグ解析」の続きです。
上記記事に書いてある不具合が再現できたので、Visual C++.NET 2003のプロセスデバッグ機能と、Heimdallrが吐き出す大量のログを使って解析してみました。
その結果、ようやく不具合を引き起こす仕組みらしきものが見えてきました。まだ特定できないのが辛いところですが。
Heimdallrは、インターネットアクセスをWinINet Functionsを使って以下の手順で行っています。
(1) InternetOpen でWinINet初期化。
(2) InternetConnect でsession handleを取得。
(3) HttpOpenRequest でHTTP request handleを取得。
(4) HttpAddRequestHeaders でrequest header設定。
(5) タイムアウトスレッド起動。タイムアウトスレッドは5秒経過したら(3)で取得したhandleに対しInternetCloseHandleを実行してスレッド終了。
(6) HttpSendRequest でrequest送信。
(7) HttpQueryInfoを何度か呼び出してresponse headerの情報を取得。
(8) InternetReadFileを呼び出してデータを受信する。読み出しバイト数として0が返ってくるまで(8)を繰り返す。
(9) タイムアウトスレッド終了。
(10) (3)で取得したhandleに対しInternetCloseHandleを実行。
(11) (2)で取得したhandleに対しInternetCloseHandleを実行。
(12) (2)~(11)を、登録されているサイトの数だけ繰り返す。(2)~(11)は、複数のスレッドで同時に実行する。
(13) (1)で取得したhandleに対しInternetCloseHandleを実行。
今回解析したところ、タイムアウトスレッドは動いていないのにInternetReadFileの呼び出しがいつまでたっても完了していないような形跡が見つかりました。
これだけの情報からどこにバグがあるのか推測してみます。
(a) InternetReadFile呼び出し中に別スレッドからInternetCloseHandleが呼ばれたときにInternetReadFileを終了できない場合がある。つまりWinINetのバグ。
(b) InternetReadFile呼び出し前にタイムアウトスレッドからInternetCloseHandleが呼ばれ、さらに別のスレッドでHttpOpenRequestが呼ばれてhandleが再利用されてしまう。InternetReadFileは準備のできていないhandleから読み出そうとしてハング。つまりWinINetの使い方のバグ。
(c) その他のWinINetの使い方に関するバグ。
(d) 上記の手順に書かれていないところにバグ。
(e) 「タイムアウトスレッドは動いていないのにInternetReadFileの呼び出しがいつまでたっても完了していない」というのがそもそも勘違い。バグは別のところにある。
(f) Heimdallrはちゃんと動いている。私の脳のバグ。
(g) その他。
へぼい仮説ばっかりですが、今まではこの程度の仮説を立てることさえできませんでした。ようやくここまできた・・・。 さて怪しそうなのは(a)~(d)あたりです。もう少し解析してみましょう。次に再現するのは一週間先かもしれませんが。
2006年05月09日
Google Calendar Data APIのお勉強
本日Google Calendar Data APIの仕様をちょっと勉強しました。
現時点で気が付いたことをあれこれ書いておきます。
まだ仕様を眺めただけであり、コードを書いて検証していないので、所々間違えているかもしれません。
- 送受信するデータの形式は基本的にAtom 1.0(RFC4287)です。
- Privateなカレンダーは、HTTPSでパスワード認証してauthorization token(文字列)を取得した後、HTTPとauthorization tokenを使ってイベントの取得/追加/変更/削除が行えます。認証トークンの有効期限については良く分かりませんでした。
- PrivateなカレンダーのPublicなイベントは、認証しないと取得できません。projectionをpublicにしてイベントを取得しようとするとステータスコード404が返ってきました。なんででしょうね?
- Publicなカレンダーは、認証せずにイベントの取得ができます。追加/変更/削除には認証が必要です。
- PublicなカレンダーのPrivateなイベントは、認証しないと取得できません。
- Privateなカレンダーは、magic-cookieと呼ばれる文字列が含まれたURLにアクセスすることにより、HTTPSによる認証を行わずに取得することができます。追加/変更/削除はできません。レガシーアプリケーション用でしょうかね。便利そうです。
- イベントの取得/追加/変更/削除はそれぞれHTTPのGET/POST/PUT/DELETEを使って行います。詳細はこちら。PUTやDELETEって一般的なHTTPプロキシは対応しているのかな。
- Calendar query parameters(start-minやstart-max)を使った範囲指定はmagic-cookieが含まれたURLを使う場合も有効です。
- Google Calendarは複数のMy Calendarを登録できますが、それぞれのMy CalendarのUserIDは異なります。最初のMy CalendarのUserIDはアカウントのメールアドレスですが、それ以外のMy CalendarのUserIDは、Googleが勝手にXXXXXXXXXXXXXXXXXXXXXXXXXX@group.calendar.google.comというUserIDを割り振ります。
- Other Calendarにも、Googleが勝手にXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX@import.calendar.google.comというUserIDを割り振ります。
- My CalendarやOther Calendarの一覧を取得する手段が分かりませんでした。アカウントを指定して全てのCalendarのUserID一覧を取得する手段が欲しいですね。これができればGoogle Calendarと表示内容を一致させたデスクトップアプリケーションが作れるのですが。
興味深いのは、Privateなイベントを認証なしに取得する手段を用意してくれているところ。 これのおかげで、Google Calendarをまったく考慮していない従来のRSSリーダーでも、Atom 1.0にさえ対応していればPrivateなイベントを取得することができます。便利ですねぇ。 もちろん、この手段を用意したために余計なセキュリティリスクを抱えこんでしまったとは思いますが、それでもこの方法を用意するあたり、Googleのセンスを感じます。
なお、このサイトで公開しているRSSリーダー Heimdallrは最新版(1.11alpha1)でもAtom 1.0に対応していませんのでGoogle CalendarのPrivateなイベントを取得することはできません。ひどいよ私。
私の手元にある未リリース版はAtom 1.0に対応していますので、次のリリースまでお待ち下さい。早めにリリースして欲しい方は要望を下さい。
2006年05月06日
飛んでいる蝶ってどうやって撮るんでしょうね
ツマキチョウが群れて飛んでいたので撮っておきたいと思ったのですが、これを綺麗に撮るのって難しいですね。
適当に撮ったらこんな感じになりました。

蝶のところだけクローズアップしてみます。

蝶だと言われれば蝶のように見えるとは言えますが、羽の模様とか全然分かりません。
飛んでいる蝶を撮るときの難しさは、第一に時間が限られていること。第二に被写体ブレが発生すること。第三にピントが合わないことです。
ピントを合わせるために絞り値を上げるとシャッタースピードが落ちてブレが激しくなる。シャッタースピードを上げるためには露出を切り詰めるかISO感度を上げるか。どうやるにしても設定に時間がかかればそこでお終い。
設定の時間については最初から飛ぶ蝶を撮るための設定にしておくことによりカバーできるのですが、やはり止まっている蝶も撮りたいので、止まっている蝶を撮るときの設定との切り替えを素早くしたいです。
こういうときのシャッター優先モードだとは思うのですが、このモードでシャッタースピードを早くすると露出アンダーになってしまいます。真っ黒な写真を撮りたいわけではないのでISO感度上げて欲しいんですけどね・・・。でも残念ながらPanasonic LUMIX DMC-FZ7はシャッター優先モードではISO感度は固定なのです。
というわけでなかなか上手く行きません。どうしたもんか。
一応、上記の写真の蝶がツマキチョウであることを証明するために、証拠写真を撮ってきました。

止まっていれば撮るのは簡単なんですけどね。
2006年05月03日
Heimdallrのバグ解析
このサイトで公開しているRSSリーダー Heimdallr ですが、既知のバグが1件あります。最新の情報に更新する処理が永遠に終わらなくなるバグです。CPU使用率が100%になるのが特徴です。
発生頻度が低く、OSはWinXP Home、登録サイト数は200、更新間隔は30分という条件で、一週間に一度発生するかしないかくらいの頻度です。
おかげでバグ解析が難航しています。まだ原因は分かっていません。
原因は分かっていませんが、なんとなくMFCのCInternetSession、CHttpConnection、CHttpFileあたりの使い方が悪いのではないかと考えています。
HeimdallrではこれらのクラスをRSS Feedを取得するために使っており、その中で受信タイムアウトを実現するために以下の処理を行っています。
- CInternetSession::GetHttpConnectionを使用してCHttpConnectionオブジェクト取得。
- CHttpConnection::OpenRequestを用いてCHttpFileオブジェクト取得。
- タイムアウト用スレッド起動。
- CHttpFileオブジェクトを用いてリクエスト送信及びレスポンス受信。
- タイムアウトスレッド起動後、一定時間経過しても受信が完了しない場合は、タイムアウトスレッドからCHttpFile::Abortを呼び出す。
最後のAbort呼び出しを別スレッドから行っているのが問題で、このような使い方をした場合、正しく動作することが保障されるとはどこにも明記されていないのです。よって、何か問題が発生する可能性もあります。でも再現性が低いため本当にこれが原因なのか確認できていないのです。さてはて・・・。
2006年05月02日
昆虫を撮る時の注意点
以前購入したPanasonic LUMIX DMC-FZ7で色々な昆虫の写真を撮ってみましたので、その注意点などを書いておきます。と言っても私はカメラに詳しいわけではないのでアテにしないで下さいね。
5cmマクロモード
一番良い撮り方は簡単です。マクロモードにして昆虫に5cmまで接近し、カメラを三脚などで固定し、昆虫が動いていないときを狙ってシャッターボタンを押すだけです。いやー簡単。
と言うのは簡単ですが、フィールドでこれを実現するのは簡単ではありません。5cmまで近づくのが困難な昆虫なんて山ほどいますし、動かなくとも風で揺れることもありますし、カメラを固定している間に逃げられることも多いです。
と言っても、マクロモード5cmはやっぱり強力ですので近寄れる相手にはこれを使いましょう。DMC-FZ7は手ブレ補正があるので、カメラをしっかり構えれば三脚がなくても結構いけます。昆虫がちょっと動いていたり、風で揺れていたりする場合は連射モード連射してマグレ当たりを狙いましょう。
5cmまで近づければ、体長は10mm位の蜘蛛もこんな感じです。

フォーカスは基本的にオートですが、この蜘蛛のように、昆虫が小さかったり細かったりする場合は、ピントが昆虫ではなく背景に合ってしまう事がよくあるので、そういったときはマニュアルフォーカスにして5cm先にピントを合わせ、カメラを昆虫の5cm付近まで近づけましょう。
1mテレマクロ
5cmまで近づけない場合に有効なのが、テレマクロです。マクロモードにして12倍ズーム(T端)にすると、テレマクロモードになります。このモードでは1m位の距離からピントが合います。このモードにして1m位の距離から撮影すると、大体10cm程度の距離から撮影した場合と同じ大きさになります。
11倍ではピントが合うのは2m位先になりますので、必ず12倍まで上げましょう。
下手な倍率で数十センチの距離から取るよりも、テレマクロモードで1mの距離から撮った方が綺麗に取れる場合が多いです。手ブレはそれなりに起こるので、連射と気合で抑えましょう。
テレマクロモードを使えば、1mまでしか近づけなくてもこんな感じで撮れます。

AFモードはスポットにしましょう。スポットにしておくと、こういう場合に蝶にフォーカスが合わせられて便利です。

なお、テレマクロモードは1m以上でも使えます。
相手が蝶や蜂など逃げやすい昆虫の場合、1mまで近寄る前に逃げられてしまうことが良くあります。撮れる時に撮りましょう。とりあえず撮ってから近づけば良いのです。
3m位離れていてもこんな感じで撮れます。チャンスがあったら、まず撮りましょう。

なお、春先に単独でうろつく巨大なスズメバチは、巣作りや子育てを控えた女王蜂です。言わば妊婦さんです。攻撃性は低いので、ちょっとだけなら近づいても平気でしょう。
でもさすがに5cmまで近づいて撮影するのは止めておきましょう。
スズメバチはさておき、昆虫を撮りたいとき、テレマクロモードは汎用性が高くて便利です。積極的に使っていきましょう。
トリミング
昆虫を相手にする場合、希望の構図で撮れない時が良くあります。例えば、もうちょっと近づいて撮りたかった思っても、相手は既に遠くに逃げ去っており、もう二度と撮れない、そんなときです。
そんなときは、なんとか撮れた写真をトリミングして、希望の構図を作ってしまいましょう。
トリミングを行うと画像はどんどん劣化していきますので、最初に撮影するときには記録画素数を最大の6Mにしておきましょう。
6Mにしておくと、トリミングしてもL版印刷に耐えられる写真になります。
試しにトリミングしてみましょう。上記のスズメバチですが、3mの距離から撮っただけあって、ちょっと小さい気がします。日本最凶の蜂らしさを出すさめ、トリミングして拡大してみましょう。

ちょっと凶悪さが増した気がします。
デジタルズーム
デジタルズームも案外綺麗です。1m位の距離からテレマクロモードで光学12倍、デジタル4倍、計48倍で撮るとこんな感じになります。

さすがにくっきりとは行きませんが、L版印刷には耐えられそうです。
ちなみにデジタルズームで撮っても、画像サイズは変わりません。ファイルサイズも同じ位です。似たような処理をしているように見えるトリミングは画像のサイズは小さくなり、ファイルサイズも小さくなります。不思議ですねぇ。
まとめ
- 可能ならば5cmの距離からマクロモードで撮影する。
- 5cmマクロモード撮影が無理ならば1m以上離れてテレマクロモードで撮影する。
- AFモードはスポット。
- 連射は基本。
- 記録画素数は6M。
- トリミングとデジタルズームは有効なので活用すること。
以上、昆虫を撮る時の注意点でした。
2006年05月01日
iCalendar(iCal)ファイルを出力するMovableTypeテンプレート
最近のエントリの情報をiCalendar(iCal)ファイルとして出力するMovableTypeテンプレートを公開します。
動作させるためには、先日公開した「MTEntryAnotherDate」プラグインが必要です。
また、文字エンコーディング方式(mt-config.cgiの設定)がUTF-8ではない場合は動作しないと思われます。
MovableTypeテンプレートは以下の通りです。
BEGIN:VCALENDAR PRODID:iCalendar Index for MovableType 3.2-ja-2 VERSION:2.0 X-WR-CALNAME:<$MTBlogName remove_html="1" strip_linefeeds="1"$> <MTEntries lastn="15"> BEGIN:VEVENT DESCRIPTION:<$MTEntryPermalink strip_linefeeds="1"$> <$MTEntryExcerpt strip_linefeeds="1"$> DTSTART:<$MTEntryDate format="%Y%m%d"$> DTEND:<$MTEntryAnotherDate format="%Y%m%d" add="86400"$> SUMMARY:<$MTEntryTitle remove_html="1"$> END:VEVENT </MTEntries>END:VCALENDAR
出力サンプルを以下のURLから取得できます。
http://www.sutosoft.com/room/index.ics
出力サンプルがGoogle Calendarから認識されることだけは確認済ですが、 iCalendarのRFC(RFC 2445)を熟読して作成したものではありませんので、本当にiCalendar形式として正しいファイルが出力されるかどうかは分かりません。