2005年02月28日
2月は毎日更新できました
今月はなんとか毎日更新することができました。
短い記事でも書くのに15分はかかりますし、長い記事だと1時間以上かかるので毎日更新は結構大変でしたが、1年のうちで1番短い月なのでちょっと踏ん張ってみました。
来月以降はこんな無茶はしません。いつも通りにのんびりと不定期に書く予定です。
2005年02月27日
MFCにおけるzlibの使い方
- 環境
- Visual C++.NET 2003
- ライブラリ
- MFC
- ライブラリ
- zlib 1.2.2
zlibという超有名なフリーの可逆圧縮ライブラリがあるのですが、今回はMFCアプリケーションにおけるこのライブラリの使い方について書いてみます。
このライブラリがサポートしている圧縮方式はDeflate/Inflate方式と言いまして、RFC1950に定義されています。この方式は実に様々なところで使われておりますが詳細は省略。さらにこのライブラリのライセンスはとても使いやすくなっていて、このライブラリは実に広く使われておりますが詳細は省略。
詳細は省略しておいてとにかくMFCアプリケーションでこのzlibを使いたいと思ったとします。
それでもってzlibをビルドし、作成されたスタティックライブラリ(zlib.lib)とMFCアプリケーションをリンクしてビルドしたとします。
そうすると、以下のような警告を見かけるかと思います。
ひどいときにはエラーまで出ます。
LINK : warning LNK4098: defaultlib 'LIBC' は他のライブラリの使用と競合しています。/NODEFAULTLIB:library を使用してください。
もし何もエラーがなければ問題ありません。もう以下の記事を読む必要はありません。速やかに作業に戻って下さい。
このエラーが出る理由は、zlib.libとMFCアプリケーションのランタイムライブラリが異なるからです。
以下、詳細を説明します。
ランタイムライブラリ
ランタイムライブラリとは、C++標準ライブラリの実行コードを収めたライブラリです。Visual C++.NET 2003では、このランタイムライブラリが6種類あります。
そんなにたくさんの種類がある理由は良く分かりません。ランタイムライブラリがたくさんあっても、開発者が混乱するだけでメリットは無いように思えます。
ランタイムライブラリを分けないとMFCが実装できなかった、等、何か止むを得ない事情があったのでしょう。
これらのランタイムライブラリは、以下のように使い分けられています。
| ライブラリ | MFCの使用 | Debug/Release | コンパイラオプション |
|---|---|---|---|
| MSVCRT.lib | 共有DLLでMFCを使用 | Release | /MD |
| MSVCRTd.lib | 共有DLLでMFCを使用 | Debug | /MDd |
| LIBCMT.lib | スタティックライブラリでMFCを使用 | Release | /MT |
| LIBCMTd.lib | スタティックライブラリでMFCを使用 | Debug | /MTd |
| LIBC.lib | 標準Windowsライブラリを使用 | Release | /ML |
| LIBCd.lib | 標準Windowsライブラリを使用 | Debug | /MLd |
MFCを使う場合と使わない場合で異なるランタイムライブラリが使用されることが分かります。
上記警告(LNK4098)が発生した理由は、zlib.libは「標準Windowsライブラリを使用」設定でビルドし、MFCアプリケーションはMFCを使用する設定でビルドしたため、zlib.libとMFCアプリケーションで異なるランタイムライブラリが使用されたからです。
やっとエラーが発生した理由が分かりました。
各ランタイムライブラリ用ライブラリの作成方法
一番簡単な解決先は、zlib.libのランタイムライブラリをMFCアプリケーションと合わせてしまうことです。
MFCアプリケーションの方はMFCを使う以上変更できないようなので、zlib.libの方を合わせます。プロジェクトの設定からC/C++→コード生成→ランタイムライブラリ の設定を、MFCアプリケーションと同じものにしましょう。これで解決です。
しかし、zlib.libの方を変えてしまうと、非MFCアプリケーションでzlib.libを使うとき同じような問題が発生します。
ではどうすれば良いかと言いますと、こんなのはどうでしょう。
ランタイムライブラリが6種類あるので、夫々のランタイムライブラリ用にzlib.libを6種類作ってしまうのです。スマートな解決方法ではありませんが、一応問題は全て解決です。
6種類のzlib.libを作成するためのVisualC++.NET 2003用のプロジェクトを作りました。zlib 1.2.2用です。他のバージョンで動くかどうかは分かりません。このプロジェクトファイルをzlib.cやzlib.hと同じフォルダに置き、開いて下さい。
開いた後、全構成のバッチビルドを行ってください。libというフォルダが作成され、その中に6つのライブラリファイルができているはずです。
zlibを使いたいときは、使う側の都合に合わせて適切なライブラリをリンクして下さい。
2005年02月26日
basic_filterbuf用ostreamクラス
以前の記事でbasic_streambufの派生クラスであるbasic_filterbufクラスを作成しました。
しかし、アプリケーションから直接basic_streambuf派生クラスを扱うのはあまりよろしくない気がします。アプリケーションからばbasic_ostream派生クラスなりbasic_istream派生クラスだけを扱うべきだと思います。なんとなく今のC++標準ライブラリからそんなポリシーを感じるためです。
というわけで、アプリケーションからbasic_filterbufの存在を隠すためのbasic_ostreamの派生クラスを作ってみました。
template <class Elem, class Tr = std::char_traits<Elem> >
class basic_ofilterstream : public std::basic_ostream<Elem, Tr>
{
public:
explicit basic_ofilterstream(basic_filterbuf<Elem, Tr>* _Buffer, bool _DeleteBuffer, std::basic_ostream<Elem, Tr>* _Stream, bool _Delete = false)
: std::basic_ostream<Elem, Tr>(_Buffer), _buffer(_Buffer), _delete_buffer(_DeleteBuffer), _stream(_Stream), _delete(_Delete)
{
}
virtual ~basic_ofilterstream(void)
{
if (_delete) {
delete _stream;
}
if (_delete_buffer) {
delete _buffer;
}
}
private:
basic_filterbuf<Elem, Tr>* _buffer;
bool _delete_buffer;
std::basic_ostream<Elem, Tr>* _stream;
bool _delete;
};
このクラスも派生させて初めて役に立つクラスです。 派生クラスのコンストラクタはこんな感じになります。
explicit basic_oxxxstream(std::basic_ostream<Elem, Tr>* _Stream, bool _Delete = false)
: basic_ofilterstream<Elem, Tr>(new basic_xxxbuf<Elem, Tr>(_Stream->rdbuf()), true, _Stream, _Delete)
{
}
basic_xxxbufというのは、basic_filterbufの派生クラスです。
basic_oxxxstreamのコンストラクタの引数を見て頂きたいのですが、引数がbasic_ostreamクラスへのポインタになっており、basic_streambufクラス及びその派生クラスを引数に取らなくなっています。
これでこうしたアプリケーションからはbasic_streambufを扱わなくて済む、というわけです。
今回作成したのは出力用クラスですが、入力用クラスもほぼ同様に作れると思いますので必要に応じて(必要な方はいないと思いますが)作ってみて下さい。
2005年02月25日
C++ストリーム用Decoratorクラス
以前の記事の続きということで、多少は役に立つオリジナル入出力クラスを作ることを考えてみます。最終的には書き込んだデータに何らかの加工を施して他のストリームに書き出すクラスを作る予定です。
こういうクラスを作る場合、最初に作るのはDecoratorクラスです。
これは、データを加工せずに他のストリームに書き出すクラスです(詳細についてはGoFのデザインパターンを見て下さい)。
加工しないのでこのクラス単体では何の役にも立ちませんが、加工をするようなクラスを作る際、このクラスを派生させて作ると楽に作れるのです。
Decoratorクラスの名前はbasic_filterbufとします。filterという名前はJavaのFilterInput/OutputStreamから貰いました。
コードは次のようになります。
(注意)本コードは正しく動作しません。詳細は「C++ストリームの拡張方法について」を参照して下さい。
template <class Elem, class Tr = std::char_traits<Elem> >
class basic_filterbuf : public std::basic_streambuf<Elem, Tr>
{
public:
explicit basic_filterbuf(std::basic_streambuf<Elem, Tr>* _Buffer, bool _Delete = false)
: _buffer(_Buffer), _delete(_Delete)
{
}
virtual ~basic_filterbuf(void)
{
if (_delete) {
delete _buffer;
}
}
protected:
virtual void imbue(const std::locale &_Loc)
{
_buffer->pubimbue(_Loc);
}
virtual std::basic_streambuf<Elem, Tr>* setbuf(char_type* _Buffer, std::streamsize _Count)
{
_buffer->pubsetbuf(_Buffer, _Count);
return this;
}
virtual pos_type seekoff(off_type _Off, std::ios_base::seekdir _Way, std::ios_base::openmode _Which = std::ios_base::in | std::ios_base::out)
{
return _buffer->pubseekoff(_Off, _Way, _Which);
}
virtual pos_type seekpos(pos_type _Sp, std::ios_base::openmode _Which = std::ios_base::in | std::ios_base::out)
{
return _buffer->pubseekpos(_Sp, _Which);
}
virtual int sync()
{
return _buffer->pubsync();
}
virtual std::streamsize xsgetn(char_type* _Ptr, std::streamsize _Count)
{
return _buffer->sgetn(_Ptr, _Count);
}
virtual std::streamsize xsputn(const char_type* _Ptr, std::streamsize _Count)
{
return _buffer->sputn(_Ptr, _Count);
}
std::basic_streambuf<Elem, Tr>* buffer(void)
{
return _buffer;
}
private:
std::basic_streambuf<Elem, Tr>* _buffer;
bool _delete;
};
なんとなく命名規則をVisualC++.NET 2003付属の標準ライブラリと合わせて見ました。
内容はそれほど難しいものではないと思いますので説明は省略します。 でもって上記しましたがこのクラス単体では役に立たないので使い方も省略します。
2005年02月24日
技術系記事のコメント
このサイトには、技術系っぽい記事がいくつか存在します。
最近の記事で言うと、
「C++の入出力関連クラス」や「オリジナル入出力クラスの作り方」がそれです。
こうした記事のの記事のアクセスカウンタは、最初はなかなか増えません。しかしGoogleからのアクセスを地道に稼ぎ、長い目で見ると他の記事のアクセス数を超える場合が多々あります。
例えば、
「今年閲覧された記事ベスト10」を見てみますと、
- VSS関連の記事
- 背景が透明なウィンドウの作り方
- Inno Setupの使用例
しかし。
コメントが無いのです。
つい最近あった山口さんからのコメントが、このサイトが今のBlog形態になって以来初のコメントになります。
このサイトが今のようになったのは2004年5月8日ですから・・・
おおよそ9ヶ月半にしてようやく1つ目のコメント、ということですね。
技術者ってシャイなのですかねぇ。
それとも参考にならない記事ばっかりなのかな?
2005年02月23日
キーワードチャンネル
最新版Heimdallrにはキーワードチャンネルというプラグインが入ってます。
機能的には別に大したものではなく、いくつかのRSS検索サイトを巡回してその結果をまとめるだけのものです。
私は、これはプラグインを作るための(私の)練習用だと考えていました。
キーワードチャンネルをしっかりと作ることにより、Heimdallrとプラグインのインターフェースが多少はまともなものになると思ったからです。
本番は、(トピックチャンネルを含め)それ以外のプラグインです。
と思っていたのですが、しっかりと作ってみると、このキーワードチャンネルは意外と便利です。
キーワードのウォッチが簡単な操作で実現できるのがポイントです。
ブラウザでRSS検索サイトのURLを開いてキーワードを入力して・・・とやれば同じことなのですが、
それよりも数クリック少ないクリック数で目的を達成できます。
つい気軽にキーワードを追加したくなります。
クリック回数の削減効果って侮れないなぁ・・・と実感した次第です。
2005年02月22日
オリジナル入出力クラスの作り方
前回の記事でC++標準ライブラリの入出力周りについて書きましたが、
そもそも入出力周りを調べようと思ったのはオリジナルの入出力クラスを作ってみようと思ったからです。
今回は、そのことについて書いてみようと思います。
最初はbasic_ostreamを派生させて作れば良いだろうと思っていたのですが、write関数がvirtualではないのでどうにもできず、色々と調べてみたところbasic_streambufというクラスの役割が分かった、ということです。
最後に一応オリジナルの入出力クラスの作り方を簡単に説明しておきます。簡単に、です。
まずはbasic_streambufを派生させた新しいクラスbasic_xxxstreamを用意し、xsputnとxgetnを実装します。
あとばbasic_ostreamのコンストラクタにbasic_xxxstreamへのポインタを渡せば後はそのままbasic_ostreamを使って入出力が行えるようです。
言葉だと分かり難いかもしれませんのでイメージが沸くようコード断片を書いてみます。
断片なので、コンパイルはできません。ご注意下さい。
#include <ostream>
// basic_xxxstreamクラス定義。本当は他にもいくつか定義する必要のある関数があります。
template <class Elem, class Tr = char_traits<Elem> >
class basic_xxxstream : public basic_streambuf<Elem, Tr>
{
virtual std::streamsize xsgetn(char_type* _Ptr, std::streamsize _Count)
{
return _buffer->sgetn(_Ptr, _Count);
}
virtual std::streamsize xsputn(const char_type* _Ptr, std::streamsize _Count)
{
return _buffer->sputn(_Ptr, _Count);
}
};
int main(void)
{
basic_xxxstream<char> xxx;
basic_ostream<char> out(&xxx);
// 後はoutを使って好きなようにデータを出力
out << 10;
out << "hogehoge";
out.flush();
return 0;
}
なんとなくイメージは沸きましたか?
コンパイル可能なコードにするためには、basic_streambufをもっと調べて他の必要な関数を書き足していって下さい。
2005年02月21日
C++の入出力関連クラス
C++の標準ライブラリには入出力関連のクラスが含まれています。 例えばファイルに出力するためのクラスはofstreamです。
といってもofstreamは本物のクラスというわけではなく、typedef basic_ofstream<char, char_traits<char> > ofstream;
と定義されていますので、basic_ofstreamテンプレートクラスがcharに特化された型となっています。
特化された型についてまで説明するとややこしくなるので、以下basic_から始まるクラスについてのみ説明します。
basic_ofstream周辺のクラス構成
basic_ofstreamに関連したクラスの構成は、以下のようになっています。
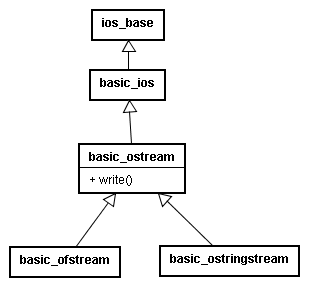
basic_ostreamというクラスが出力関連クラスの基底クラスになっているようです。
そしてここにwriteという出力用関数があります。
私は、最初このwriteが出力用の中核となる関数だと思っていました。
Javaで言えばjava.io.OutputStreamクラスのwrite、MFCで言えばCFileクラスのWrite、どちらも出力用の中核となる関数です。
ところが、このbasic_ostreamのwriteは、virtual関数では無いのです。
virtualでは無いということは、派生クラスで処理内容を変えられないということです。
basic_ofstreamは、どうやってファイルにデータを出力しているのでしょうか?
basic_ostringstreamは、どうやってメモリにデータを出力しているのでしょうか?
そこらへんに疑問を持ちましたので、ちょっと調べてみました。
入出力関連クラス構成
入出力関連クラスの構成は結局こんな感じになっているようです。
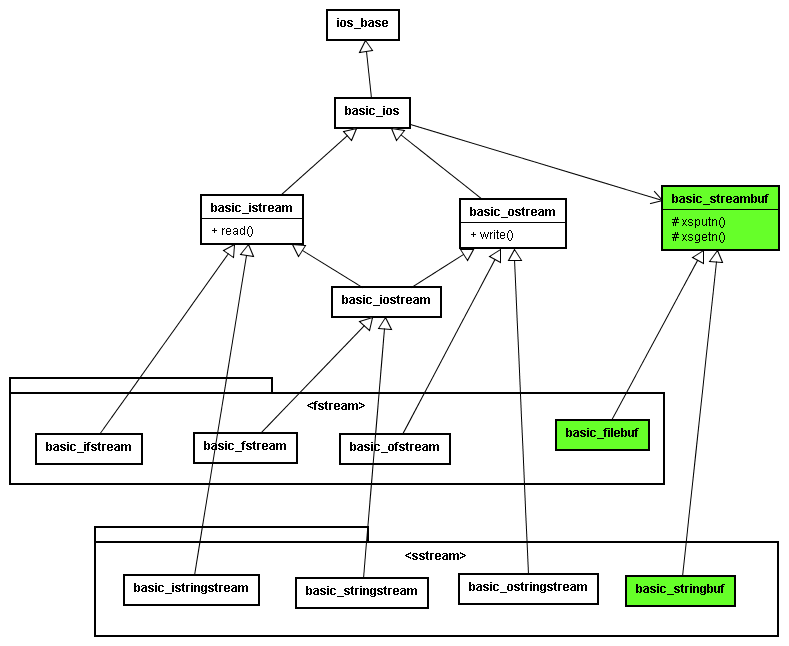
でもってvirtualなwrite関数も見つけました。 basic_streambufクラスのxputnとxgetnです。 どうやらこれらの関数こそが入出力処理の中核になっているようです。
basic_ostreamやbasic_istreamから派生したクラスは、どうもbasic_streambufのラッパでしかないようです。Javaで言えば、ObjectOutput/InputStreamに相当するクラスみたいです。
basic_streambufから派生したbasic_filebufやbasic_stringbufが真の(?)入出力処理を行うクラスのようですね。
basic_streambufよ・・・お前が犯人か・・・
2005年02月20日


2005年02月19日
MTのコメントRSS化テンプレート
「MTのコメントをRSS化」を参考に、MovableType専用のコメントのRSS作成用テンプレートを作ってみました。
参考元のRSS FeedはRSS 2.0準拠ですが、なんとなくRSS1.0に準拠したものを作成してみました。RSSのバージョンなんて何でも良いと思いますけどね。
完成品はこちらです。
comments.rdf
作り方
最初に適当なインデックス・テンプレートを作ります。
テンプレートの名前と出力ファイル名はなんでも良いです。
私はテンプレートの名前は「RSS 1.0 Comments」ファイル名は「comments.rdf」にしました。
テンプレートの中身は以下の通りです。
<?xml version="1.0" encoding="<$MTPublishCharset$>"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:admin="http://webns.net/mvcb/" xmlns:cc="http://web.resource.org/cc/" xmlns="http://purl.org/rss/1.0/"> <channel rdf:about="<$MTBlogURL$>"> <title><$MTBlogName remove_html="1" encode_html="1"$> コメント</title> <link><$MTBlogURL$></link> <description><$MTBlogName remove_html="1" encode_html="1"$>の最新のコメント</description> <dc:language>ja</dc:language> <dc:date><MTComments lastn="1"><$MTCommentDate format="%Y-%m-%dT%H:%M:%S" language="en"$><$MTBlogTimezone$></MTComments></dc:date> <admin:generatorAgent rdf:resource="http://www.movabletype.org/?v=<$MTVersion$>" /> <MTBlogIfCCLicense> <cc:license rdf:resource="<$MTBlogCCLicenseURL$>" /> </MTBlogIfCCLicense> <items> <rdf:Seq><MTComments lastn="15" sort_order="descend"> <rdf:li rdf:resource="<MTCommentEntry><$MTEntryPermalink encode_xml="1"$>#comment_<$MTCommentID pad="1"$></MTCommentEntry>" /> </MTComments></rdf:Seq> </items> </channel> <MTComments lastn="15" sort_order="descend"> <item rdf:about="<MTCommentEntry><$MTEntryPermalink encode_xml="1"$>#comment_<$MTCommentID pad="1"$></MTCommentEntry>"> <title><$MTCommentAuthor default="" remove_html="1" encode_xml="1"$>(<MTCommentEntry><$MTEntryTitle remove_html="1" encode_xml="1"$></MTCommentEntry>)</title> <link><MTCommentEntry><$MTEntryPermalink encode_xml="1"$>#comment_<$MTCommentID pad="1"$></MTCommentEntry></link> <description><$MTCommentBody remove_html="1" encode_xml="1"$></description> <dc:date><$MTCommentDate format="%Y-%m-%dT%H:%M:%S" language="en"$><$MTBlogTimezone$></dc:date> </item> </MTComments> </rdf:RDF>
あと、Individual Entry Archiveテンプレートも編集する必要があります。
コメントのURLを決めるためです。
<MTComments>と</MTComments>で囲まれたところのどこかに
<a name="comment_<$MTCommentID pad="1"$>"></a>
という一行を追加します。私は、<div class="comments-body">の直後に追加しました。
これで完成です。サイトの再構築をしてみて下さい。 コメント用RSS Feedが作成されているはずです。
2005年02月18日
ニュースサイト調査(2/2)
前回の続きです。
今回の調査項目は、「BLOGサービスの調査」と同様です。
調査結果
| ニュースサイト名 | If-Modified-Since | If-None-Match | gzip | deflate | compress |
|---|---|---|---|---|---|
| CNET Japan | ○ | ○ | × | × | × |
| asahi.com | ○ | ○ | × | × | × |
| MYCOM PC WEB | ○ | × | × | × | × |
| 日経BP-RSS | ○ | × | × | × | × |
| WIRED NEWS | ○ | × | × | × | × |
| スラッシュドット ジャパン | ○ | ○ | ○ | × | × |
| 夕刊フジBLOG | ○ | ○ | × | × | × |
| デジタルARENA・総合 | ○ | ○ | × | × | × |
| @IT | ○ | ○ | × | × | × |
考察
流石に全サイト(9/9)If-Modified-Sinceに対応してますね。If-None-Matchは6/9ですが、If-Modified-Sinceに対応していれば事足りるでしょうから問題なさそうです。
gzip対応はやっぱり少ないです。対応しているのはスラッシュドット ジャパンだけで1/9です。
RSSリーダーとしては、If-Modified-Since対応は必須、If-None-Match対応は必要無くてgzipは余裕が有り余っていたら、というあたりになると思います。
その他
MYCOM PC WEBとWIRED NEWSはETagは返すのですが、If-None-Matchには反応しません。Etagもったいないですね。
日経BP-RSSは毎回異なるETagを返します。使い方が難しいですね。
2005年02月17日
ニュースサイト調査(1/2)
以前、RSSを出力するサービスの調査の一環として、「BLOGサービスの調査」を行いました。
今回は、RSSを出力するニュースサイトについて調べてみようと思います。
今回は以下のような条件でニュースサイトを抽出しました。
- Headline.jpのランキングに入っていること。
- Bulkfeedsなど、ニュース提供者以外がFeedを生成しているニュースサイトは除く。
- 複数人で作っているような感じがしてなんとなく公共性の高そうなニュースサイト。
曖昧な条件なので取りこぼしがあるかもしれませんが、見た感じ主なニュースサイトは抑えてあるのではないかと思います。
OPMLも作成しておきました。ご活用下さい(?)。
調査結果は次回報告します。
2005年02月16日
ダウンロード、インストール、初期化
こちらのエントリを見てだいぶヘコみました。
「RSSリーダー導入~」
なんというか、ああまたやってしまった・・・という感じです。
「MASATOの開発日記」を提供しているサーバは普通のPCですし、インターネットへの接続も普通のADSLです。
安定性にあまり期待はできません。
その上、Heimdallrは、自動学習機能のために巨大な辞書を持っていますので、今や配布用パッケージは3MByteを超えてしまっています。場合によってはダウンロードに失敗することもあるでしょう。
私は、この「ダウンロード」と、「インストール」「初期化」の3つに関するトラブルに対しては、優先的にサポートしようと考えております(初期化というのは実行ファイルが起動してビューが表示されるまでの処理のことです)。
というのも、この3つのなかで、何かトラブルがあると、大抵のユーザはその時点で使うのを諦めてしまうからです。
使った上で他のRSSリーダーの方が合っているからという理由で捨てられるのは十分に納得行きますが、使う所まで到達するより前に諦められてしまったら悲しいものがあります。
といっても、これらの処理は、ユーザの環境に依存したトラブルが多いところなのでサポートも難しいんですけどね。
とりあえず今回の問題の解決を目指し、Heimdallr配布用パッケージの置き場所を変えました。
一応プロバイダが提供しているホームページ用の場所なので、ここよりは安定しているはずです。
2005年02月15日
Aggregationモジュール
RSS 1.0にはDublin CoreやContentなど、Standardに分類されているモジュールがあります。これらのモジュールは良く使われていますが、この他に、Proposedに分類されているモジュールが結構数があります。提案されているけれどまだ正式には組み入れられていない仕様、ということでしょう。
「RDF Site Summary 1.0 proposed modules」
その中に、Aggregationというモジュールがあります。
このモジュールは、RSS検索サイトのようなあちから記事を集めてきて、1つのRSS Feedとしてまとめるときに有効です。
例を見てみましょう。FeedbackでHeimdallrを検索し、結果から一部抜粋してみます。
<item rdf:about="http://www.sutosoft.com/room/archives/000132.html"> <title>次のチャンネル</title> <link>http://www.sutosoft.com/room/archives/000132.html</link> <description>現在、HeimdallrのPluginとしてキーワードチャンネル、トピックチャンネルの2つをリリースしています。 次に来るのは何か、という話ですが、次のチャンネルも、一応決まっています。 それはmixiチャンネルです。</description> <ag:source>MASATOの開発日記</ag:source> <ag:sourceURL>http://www.sutosoft.com/room/</ag:sourceURL> <ag:timestamp>2005-02-05T00:47:47+09:00</ag:timestamp> <dc:subject>MASATOの開発日記</dc:subject> <dc:publisher>MASATOの開発日記</dc:publisher> <dc:creator>MASATO</dc:creator> <dc:date>2005-02-06T00:44:42+09:00</dc:date> </item>
要素名のプレフィックスがag:になっている要素がいくつかあります。 これにより、この記事のソースはどこか、ということが示されます。
実はHeimdallrは1.06からこのAggregationモジュールに対応しています。
いや、対応していたつもりでした。
概要ウィンドウに以下のようにこっそりag:sourceにより示される記事ソースが表示されるはずでした。

つもりでした、はずでした、というのはどういうことかと言いますと、前確認したときは表示できていたのですが、1.08alpha4で試してみたら表示できていなかったのです。
原因を解析して分かったのですが、どうやらFeedbackがAggregationモジュールの名前空間を切り替えたようです。今は、
xmlns:ag="http://purl.org/rss/1.0/modules/aggregation/"
となっていますが、昔は
xmlns:ag="http://purl.org/rss/modules/aggregation/"
だったと思います。
さすがにこれを切り替えられたら読み込めません。仕様でも変わったのかと確認してみると・・・
なんと、
「名前空間名宣言」と、「サンプル」のところで違う名前空間名を使ってます。
勘弁して欲しいなぁ・・・
曖昧な仕様書が招く小さな(ホントに小さな)悲劇でした。
どちらの名前空間名も仕様書に載っているからにはどちらかが間違いだとも言い難いです。
結局どちらでもうまくいくようにしましたので次のバージョンでは直っていると思います。
なお、このAggregationモジュールを使っているのは、 私が知っている限りFeedbackだけがこのAggregationに対応しています。なんというかさすがFeedback。
2005年02月14日
Heimdalr 1.08alpha4リリース
Heimdallr 1.08alpha4をリリースします。
安定版ではありません。
安定版はHeimdallr 1.07です。
今回の主な変更はキーワードチャンネルの強化です。だいぶ使いやすくなったのではないかと思います。キーワードチャンネルは(問題がなければ)これで完成です。
1.08alpha3→1.08alpha4の変更点詳細
- キーワードチャンネルの強化。ダウンロード時間を短縮化し、検索結果の安定性を向上させました。ダウンロードにやたらと時間がかかったり、既に見た記事が何度も表示されるという現象がだいぶ改善されるはずです。
- 記事があるのとき最上位になるはずのビューが、普通のビューになるバグを修正しました。
- Win9xにおいて上書きインストールに失敗するバグを修正しました。その代わり、Win9xでChannelExtension(特にトピックチャンネル)を使っていると、終了にとても時間がかかる場合があります。
2005年02月13日
BLOGサービス調査(2/2)
前回の続きです。
調査項目及び調査方法
以下の5項目を調査しました。- If-Modified-Sinceの対応
レスポンスヘッダにLast-Modifiedフィールドが含まれており、かつ、それを次のリクエストヘッダのIf-Modified-Sinceフィールドに設定したとき、ステータスコード304が返ってくれば○、どれかが欠けていれば×です。
調べる直前にFeedが更新されることも考え、ステータスコード200が返ってきた時にLast-Modifiedが変化していれば、再度チェックします。 - If-None-Matchの対応
Last-Modifiedの代わりにETagを見て、If-Modified-Sinceの代わりにIf-None-Matchを使うこと以外はIf-Modified-Sinceと同様です。 - Accept-Encoding: gzipの対応
リクエストヘッダのAccept-Encodingフィールドにgzipを設定したとき、レスポンスヘッダのContent-Encodingフィールドがgzipになっていれば○、そうでなければ×です。 - Accept-Encoding: deflateの対応
gzipではなくdeflateを使う以外はgzipと同様です。 - Accept-Encoding: compressの対応
gzipではなくcompressを使う以外はgzipと同様です。
調査結果
以上の調査方法に基いてテストするスクリプトを書いて走らせてみたところ、 以下のような結果になりました。
| BLOGサービス名 | If-Modified-Since | If-None-Match | gzip | deflate | compress |
|---|---|---|---|---|---|
| AOLダイアリー | ○ | ○ | × | × | × |
| ブログ人 | ○ | × | × | × | × |
| Yahoo!ブログ | × | × | × | × | × |
| LOVELOG | ○ | ○ | × | × | × |
| JUGEM | ○ | ○ | × | × | × |
| ココログ | ○ | ○ | ○ | × | × |
| ウェブリブログ | ○ | × | × | × | × |
| DoBlog | ○ | × | × | × | × |
| ドリコムブログ | ○ | ○ | × | × | × |
| エキサイトブログ | × | × | × | × | × |
| BLOCKBLOG | × | × | × | × | × |
| gooブログ | × | × | × | × | × |
| はてなダイアリー | × | × | × | × | × |
| ヤプログ | ○ | ○ | × | × | × |
| NAVERブログ | × | × | × | × | × |
| 楽天広場 | × | × | × | × | × |
| SweetBox | ○ | ○ | × | × | × |
| のブログ | × | × | × | × | × |
| ブログ通信 | × | × | × | × | × |
| 信州FM | × | × | × | × | × |
| News-Handler | × | × | × | × | × |
| バニー | × | × | × | × | × |
| シーサー・ブログ | ○ | ○ | × | × | × |
| FC2 ブログ | × | × | × | × | × |
| すくすくブログ | × | × | × | × | × |
| 関西どっとコムblog | × | × | × | × | × |
| アメーバブログ | × | × | × | × | × |
| bloguru | ○ | ○ | × | × | × |
| 尾道Blog | × | × | × | × | × |
| JENS WeBlog | ○ | ○ | × | × | × |
| ele-log | ○ | ○ | × | × | × |
| 2ch Blog | ○ | ○ | × | × | × |
| Autopage | ○ | ○ | × | × | × |
| じゃくしー | ○ | ○ | × | × | × |
| melma blog | × | × | × | × | × |
| moblo | × | × | × | × | × |
| livedoor Blog | ○ | ○ | × | × | × |
| Diarynote | × | × | × | × | × |
考察
If-Modified-Sinceに対応しているのは18/38、If-None-Matchは15/38。結構少ないですね。
まずこれらのフィールドを使うことによる効果について考えてみます。
RSS Feedは、少ないもので5Kバイト、普通は10Kバイトあたり、多いもので100Kバイトに到達します。
ステータスコード200を返すときは全部送られますが、ステータスコード304を返すときはヘッダだけなので200バイト弱のデータで済みます。ということは、データ量が1/25倍~1/500倍になるわけです。
素人考えながら、とても効果が大きい気がします。
なお、If-None-Matchに対応しているサービスは、If-Modified-Sinceにも対応していますので、RSSリーダーがIf-None-Matchに対応する必要はなさそうです。If-Modified-Sinceで十分ですね。
それでもって、Accept-Encodingに対応しているのがココログしかありません。1/38です。
これはびっくりです。
RSSリーダー側の対応も(調べてませんが)弱いと思いますが、まさかこれだけ数あるサービスのうち1つだけとは・・・。何か対応してはまずい理由でもあるんですかね。
ちなみにgzip圧縮された場合、データ量は1/3~1/4になっています。
If-Modified-Sinceほどの効果はないですね。
しかしこれだけサービス側の対応が弱いと、RSSリーダー側もまだgzipに対応する必要は無いのかもしれませんね。鶏が先か卵が先かという話かもしれませんが。
BLOGサービス提供者さんがこの記事を読むことになるのかどうかは分かりませんが、
とりあえず一言。
If-Modified-Sinceだけでも対応しませんか。
特に「gooブログ」や「はてなダイアリー」など大勢のユーザを抱えている所は。
結構な帯域節約になるのではないかと思います。
その他色々
deflateやcompressに対応したサービスはありませんが、そもそもdeflateやcompressに対応したサイトって見たことありません。Googleもgzipだけです。gzipだけあれば十分ということなんでしょうね。
「ブログ人」と「ブログ通信」は、If-None-Matchに×が付いてますが、実はETagには対応しているのです。でもIf-None-Matchには未対応。何のためのETagなんだろう・・・。
Accept-Encodingに対応しているサイトがほとんど無いため、調査用スクリプトの方を疑って色々調べているときに分かったのですが、GoogleのトップページってAccept-EncodingだけではなくUser-Agentまで見てgzipで圧縮するかどうか決めているみたいですね。User-AgentがTest Applicationのときは圧縮してくれませんでしたが、Firefoxと同じものにしてみたら圧縮してくれました。不思議不思議。
2005年02月12日
BLOGサービス調査(1/2)
以前の記事「RSS検索サイトはステータスコード304を返すか」と「RSS検索サイトは検索結果を圧縮して返すか」において、RSS検索サイトの機能について調べました。
その続きということで、他のRSSを出力するサービスについても調べてみたいと思います。
RSSを出力するサービスでもっともユーザ数が多いのは恐らくBLOGでしょう。ということでまずはBLOGを調べてみます。
と言ってもBLOGかどうかという判断が難しいときもありますので、
日記のようなコンテンツを管理するのに適しており、かつRSSが配信できるサービスをここではBLOGと呼ぶことにします。
以下のサイトを参考にしてBLOGサービスを探しました。
でもってそのサービスが出力しているRSS Feedをどれか1つ選びました。以下これを代表RSS Feedと呼びます。
同じサービスであれば、どのRSS Feedを見てもLast-Modifiedがあるかとかそこらへんは同じだと思いますので、どうやって選んでも良いと思うのですが、
今回は次のように選びました。
私がそのBLOGサービスのトップページを見たとき、
人気順のランキングがあれば、そこで1番のBLOGのRSS Feedを選びました。
ランキングが無ければ、もっとも最近更新されたBLOGのRSS Feedを選びました。
そうやって作られたリストを以下に示します。
こ、こんなにあるのか・・・
と、とりあえず今回はここまでにします。
2005年02月11日
GoogleにHeimdallr開発者として認めて貰えました
GoogleでRSS Heimdallrで検索した結果でようやくトップになりました(2/11 0:40現在)。
やっとGoogleにHeimdallr開発者として認めて貰えたようです。
これでHeimdallr普及のマイルストーンを一つ達成しました。
マイルストーンを復習してみますと、こんな感じです。
- 窓の杜に掲載される(達成済)。
- Heimdallrのことを知らないはずの会社の同僚から突っ込みを受ける(達成済)。
- GoogleでRSS Heimdallrで検索してMASATOの開発日記がトップになる(達成済)。
- VectorライブラリをRSSで検索してトップになる(達成済、もうトップじゃないですけど)。
- Vector新着ソフトレビューに掲載される。
- どこかのニュースサイト(IT Mediaとか)がやるであろう今年のRSSリーダー総括編に掲載される。
あと2つですね。別に全部達成しても何も起こりませんが。
そういえば今年のRSSリーダー総括編は、主なニュースサイトはどこもやりませんでしたね(たぶん)。
数が多すぎて手に負えなくなったのかな。
今後もやらなかったら最後のマイルストーンは永遠に達成できなくなりますね。うーん。
2005年02月10日
キャンセルボタン
Heimdallrのビュー設定ダイアログにはキャンセルボタンがついています。
ビュー設定ダイアログとは、タスクトレイのアイコンを右クリックしてビュー設定を選択したときに表示されるダイアログのことです。
このダイアログの内部は、Heimdallrの中でも2位~3位を争う複雑なものになっています。
なぜそれほど複雑になっているかと言いますと、各ビュー毎に各サイトの表示/非表示を設定できるという概念自体が複雑なことに加えて、キャンセルボタンがあるからです。
キャンセルボタンがあるということは、ユーザが行うありとあらゆる処理を、OKが押されるまで確定できないということです。特にビューやサイトを削除されたときの処理がややこしいですね。
また、このビュー設定ダイアログは、その裏では「最新の情報に更新」ができたり、記事をクリックしてブラウザを開くことができるようになっています。
当たり前のようにできそうに見えて、これを実現するのは結構大変でした。今まさにユーザが設定しようとしているデータが、裏では更新されている場合があるわけです。こうした事態をうまく処理するための複雑な処理が、キャンセルボタンのための複雑さと重なり、Heimdallrの中でもトップクラスの複雑さを持った部分になってしまっているのです。
キャンセルボタンが無くてもそれなりに複雑な部分にはなっていたと思いますが、それでも複雑さが半分くらいになっていたのではないかと思います(複雑さってなんだと突っ込まれても困りますが)。
というわけで、何気なくあるようなキャンセルボタンですが、それを維持するために結構な労力を払っています。
このビュー設定ダイアログは、おそらくHeimdallr1.10か1.11あたりで作り直されると思います。そのときキャンセルボタンがあったら、ああ頑張ったんだなぁと思ってください。キャンセルボタンがなければ、ああ諦めたんだなぁと納得して下さい。
2005年02月09日
横取り丸とInetSpy
今回は私がHTTPプロトコル解析に使っているツールを紹介したいと思います。
秀まるおさんの横取り丸とInetSpyを組み合わせて使っています。InetSpyが横取り丸のプラグインのような感じになっています。
HTTPクライアント開発者にとってはとても便利だと思います。
HeimdallrもHTTPクライアント(というかクライアント型RSSリーダーは全てHTTPクライアント)ですので、私も大変便利に使わせて頂いております。
このツールは、プロキシとして機能します。
例えば、ローカルホストにインストールし、IEのプロキシの設定をlocalhost:8000(ポート番号は変更可能)にすると、このツール経由で外にアクセスするようになります。
ツール経由のアクセス内容は全て記録されますので、それを見てあれこれ解析できます。
「RSS検索サイトはステータスコード304を返すか」という記事や、「RSS検索サイトは検索結果を圧縮して返すか」という記事にあるHTTPリクエストやレスポンスは、これらのツールを使って取得しました。
スクリーンショットを以下に示します。
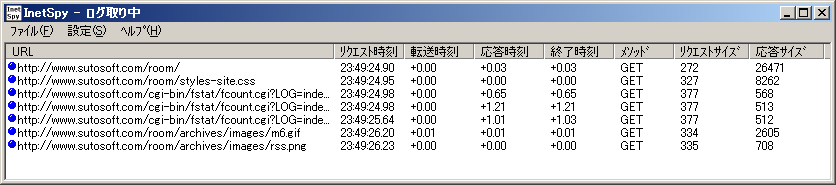
これはリクエスト一覧です。
応答時刻や終了時刻を確認することにより、HTTPクライアント開発者にとっては、ちゃんとタイムアウトしたらコネクションを切断しているのか、といったことが確認できます。
応答サイズも確認できますので、適切なバッファサイズや、If-Modified-Sinceによるメリットなどが確認できます。
個々のリクエストの詳細ももちろん確認できます。
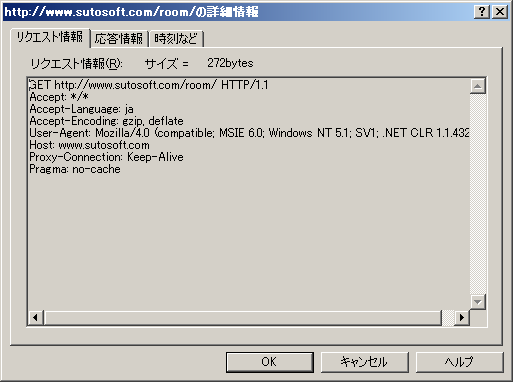
自分で作ったアプリケーションであっても、HTTP周りは他者が作成したライブラリを使うことも多いため、どのようなリクエストを出しているのかソースコードを眺めていても分かり難いものです。
考えたとおりのリクエストになっているか確認しておきましょう。
レスポンスも確認できます。
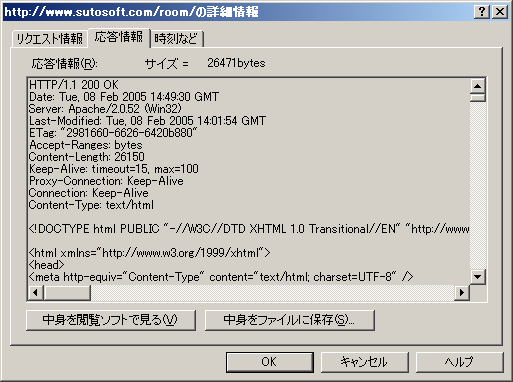
レスポンスは接続先によって様々なものになるので、細かく確認してもあまり意味は無いかもしれませんが、ステータスコード304などを確認するときに便利です。
他にも様々な活用方法があると思います。お試し下さい。
2005年02月08日
RSS検索サイトは検索結果を圧縮して返すか
前の記事ではRSS検索サイトがステータスコード304を返すか調べましたが、今回はRSS検索サイトが検索結果を圧縮して返すかどうか調べてみようと思います。
検索結果を圧縮して返す、というのは、Accept-Encoding付きのHTTPリクエストを送ると、ちゃんと検索結果(コンテンツ)をAccept-Encodingにより示された方法でエンコードして返してくれるか、ということです。
といっても、Heimdallrまだ本体がAccept-Encodingに対応していないので、今回の結果がどうあれ、キーワードチャンネルがすぐAccept-Encodingに対応することは無いです(本体が先です)。
さて、HTTP 1.1のAccept-Encodingに指定できる値を見てみると、以下の4つです。
gzip compress deflate identity
identityは、圧縮せずに結果を返せ、という意味を持っていますのでこれについては特に調べません。残りの3つを調べます。
調べ方は、まず以下のようなリクエストをサーバに送信します。
GET http://naoya.dyndns.org/feedback/app/rss?keyword=RSS HTTP/1.1 Accept-Encoding: gzip User-Agent: Test Application Host: naoya.dyndns.org Pragma: no-cache
URLとAccept-Encodingフィールド、Hostフィールドは変化します。
でもってレスポンスヘッダにContent-EncodingフィールドがあればOKとします。データが正確に圧縮されているのかどうかはややこしいので見ないことにします。ランダムっぽいデータであれば良いでしょう。
Feedback
gzipの場合のレスポンスは以下の通り
HTTP/1.1 200 OK Date: Tue, 08 Feb 2005 12:50:28 GMT Server: Apache/1.3.28 (Unix) mod_gzip/1.3.26.1a mod_perl/1.29 Vary: * Last-Modified: Tue, 08 Feb 2005 12:05:45 GMT Content-Type: text/xml; charset=UTF-8 Content-Encoding: gzip Content-Length: 3763 X-Pad: avoid browser bug
ばっちり対応しています。データもランダムっぽいのでOKでしょう。
X-Padフィールドがちょっと謎ですが、
古いNavigatorのバグ回避用のようですね。へぇ。
gzip以外のレスポンスは以下の通り
HTTP/1.1 200 OK Date: Tue, 08 Feb 2005 12:51:01 GMT Server: Apache/1.3.28 (Unix) mod_gzip/1.3.26.1a mod_perl/1.29 Vary: * Last-Modified: Tue, 08 Feb 2005 12:05:45 GMT Content-Type: text/xml; charset=UTF-8 Transfer-Encoding: chunked
残念ながら対応無し。
Serverフィールドからするとmod_gzipが入っているようなのでそれが機能しているだけなのかもしれませんね。でもgzipに対応していれば十分でしょう。
Bulkfeeds
どの場合もレスポンスは以下の通り
HTTP/1.1 200 OK Date: Tue, 08 Feb 2005 13:32:39 GMT Server: Apache/1.3.33 (Unix) mod_perl/1.29 Content-Type: text/xml; charset=utf-8 X-Cache: MISS from bulkfeeds.net Transfer-Encoding: chunked
残念ながらAccept-Encodingには対応していないようです。
未来検索livedoor
どの場合もレスポンスは以下の通り
HTTP/1.1 200 OK Date: Tue, 08 Feb 2005 13:36:10 GMT Server: Apache/1.3.31 (Unix) mod_perl/1.29 Set-Cookie: sledge_sid=c0d1b004b3b68b24b952baff2448a9f8; path=/ Content-Length: 7618 Content-Type: text/xml; charset=UTF-8 X-Cache: MISS from rss.sf.livedoor.com
残念ながらAccept-Encodingには対応していないようです。
未来検索livedoorは、Bulkfeedsから派生したという話ですが、Bulkfeedsには無いContent-Lengthを返しますね。マメですね。
ところでこのクッキー情報は何に使っているのでしょうねぇ・・・
もぶろげっと β
どの場合もレスポンスは以下の通り
HTTP/1.1 200 OK Date: Tue, 08 Feb 2005 13:40:07 GMT Server: Microsoft-IIS/6.0 X-Powered-By: ASP.NET X-AspNet-Version: 1.1.4322 Set-Cookie: ASP.NET_SessionId=1tbq5rm1nz3pxsfjszjjnyyv; path=/ Cache-Control: private Content-Type: application/xml; charset=utf-8 Content-Length: 15218
これも残念ながらAccept-Encodingには対応していないようです。
ところでこれにもクッキー情報があります。
でもASP.NETによって作られているところを見ると、ASP.NETが勝手に付けちゃった、という気もしますね。
結論
というわけで、Feedbackがgzipに対応しているだけ、という結果になりました。RSS検索サイトって結構トラフィック多いような気がするんですけど大丈夫なんですかね。
しかし、前の記事記載のIf-Modified-Sinceの件といい、Feedbackのシステムはしっかりとしてますね。細かいところまで配慮が行き届いているような気がします。唯一隙があるとしたらContent-Lengthを返さない(gzipの場合以外)ことくらいでしょうか。
細かいところまでの配慮と言っても、Apacheが勝手にやっているのかもしれません。私はApacheが付けたフィールドと、検索システムが付けたフィールドを切り分けできません。
でも、同じApacheを使っていてもBulkfeedsや未来検索livedoorは同じようになっていないわけですから、きっとFeedback開発者のnaoyaさんが、しっかりとApacheを使いこなした上で、検索システムもしっかりと作っているのでしょう。凄いなぁ。
2005年02月07日
RSS検索サイトはステータスコード304を返すか
キーワードチャンネル高速化のために、If-Modified-Sinceを使うことを考えてみました。これを使えば、検索結果が前回と変わっていなければ検索サイトはステータスコード304(Not Modified)とレスポンスヘッダだけを返し、検索結果本体は転送されないので転送時間が短縮されます。
そこで気になったのが、検索サイトはステータスコード304を返すのかどうか、ということです。検索サイトは動的に検索結果を生成していると思いますので、開発者がちょっとうっかりしていると304を返さない検索サイトが出来上がるでしょう。
では、一つずつ見ていきます。
調べ方は、各検索サイトが出力するRSS FeedのURLをHeimdallrに登録し、連続で「最新の情報に更新」を実行します。このとき送信されるHTTPリクエストヘッダと受信したレスポンスヘッダを見て判断します。
Feedback
初回のリクエストに対するレスポンスヘッダは以下の通り
HTTP/1.1 200 OK Date: Sat, 05 Feb 2005 09:38:01 GMT Server: Apache/1.3.28 (Unix) mod_gzip/1.3.26.1a mod_perl/1.29 Vary: * Last-Modified: Sat, 05 Feb 2005 09:14:52 GMT Content-Type: text/xml; charset=UTF-8 Proxy-Connection: close Connection: close
Last-Modifiedフィールドの値を次のリクエストのIf-Modified-Sinceフィールドに渡してみると、レスポンスヘッダはこうなります。
HTTP/1.1 304 Not Modified Date: Sat, 05 Feb 2005 09:38:08 GMT Server: Apache/1.3.28 (Unix) mod_gzip/1.3.26.1a mod_perl/1.29 Proxy-Connection: close Connection: close Vary: *
完璧ですね。ステータスコードは304になっています。
Bulkfeeds
初回のリクエストに対するレスポンスヘッダは以下の通り
HTTP/1.1 200 OK Date: Sat, 05 Feb 2005 09:43:30 GMT Server: Apache/1.3.33 (Unix) mod_perl/1.29 Content-Type: text/xml; charset=utf-8 X-Cache: MISS from bulkfeeds.net Proxy-Connection: close Connection: close
残念ながらLast-Modifiedフィールドがありません。 そのためIf-Modified-Sinceフィールドの設定ができず、毎回データを取得しまっているようです。
未来検索livedoor
初回のリクエストに対するレスポンスヘッダは以下の通り
HTTP/1.1 200 OK Date: Sat, 05 Feb 2005 09:51:10 GMT Server: Apache/1.3.31 (Unix) mod_perl/1.29 Set-Cookie: sledge_sid=47341abc81555667821d40239b66ad36; path=/ Content-Length: 7290 Content-Type: text/xml; charset=UTF-8 X-Cache: MISS from rss.sf.livedoor.com Proxy-Connection: close Connection: close
残念ながらLast-Modifiedフィールドがありません。
もぶろげっとβ
キーワードチャンネルではもぶろげっとβは使用しておりませんが、試しにこれも調べてみます。
初回のリクエストに対するレスポンスヘッダは以下の通り
HTTP/1.1 200 OK Proxy-Connection: close Connection: close Date: Sat, 05 Feb 2005 09:46:28 GMT Server: Microsoft-IIS/6.0 X-Powered-By: ASP.NET X-AspNet-Version: 1.1.4322 Set-Cookie: ASP.NET_SessionId=35fux3iiqlsf5uq2bcmbghns; path=/ Cache-Control: private Content-Type: application/xml; charset=utf-8 Content-Length: 15135
これも残念ながらLast-Modifiedフィールドがありません。
全然話と関係ありませんがもぶろげっとってIIS + ASP.NETで作られているんですね。
結論
というわけで、If-Modified-Sinceが使えるのは(というかLast-Modifiedが分かるのは)Feedbackだけです。これだけ高速化してもあまり意味がないので、キーワードチャンネルのIf-Modified-Since対応は後回しにしたいと思います。
2005年02月06日
キーワードチャンネル性能向上の取り組み
Heimdallrのプラグインにキーワードチャンネルというものがあるのですが、
これの性能を向上させる方法を考えてみます。
このプラグインは、ユーザから与えられたキーワードを元に、未来検索Livedoor、Bulkfeeds、Feedbackの3つの検索サイトにアクセスして結果を取得するという処理を行っています。
現在は、これら3つのサイトに同時にアクセスし、全部のサイトから結果が返って来たら終了、という処理を行っています(以下、これをダウンロード処理とします)。
さて、こうした処理のどの性能を向上させるか、という話ですが、
ユーザからもっとも目立つのはメモリの量やCPU負荷ではなく、ダウンロード処理時間が長いことですので、最初にこの時間を短縮させるべきでしょう。
どうやって短縮させるかという話ですが、
まずその前にどうして時間がかかっているのか調べてみました。
その結果、RSS検索サイトが結果を返すまでに時間がかかる場合が時々あることと、エラーが発生したときに特に時間がかかることが分かりました。
検索サイトが結果を返すまでに時間がかかった場合、ダウンロード処理の時間が長くなってしまうのは仕方がないことですが、それでも多少は改善することができます。
例えばこんなのはどうでしょう。
いつも3つのサイトにアクセスするのではなく、最初のダウンロード処理では未来検索Livedoor、次はBulkfeeds、最後はFeedback、そして最初に戻る、というような感じで、ダウンロード処理1回につき1つの検索サイトにしかアクセスしないようにするのです。
その1回に時間がかかった場合は仕方が無いですが、ダウンロード処理時間の平均は改善すると思います。
最新の検索結果がすぐに得られないという欠点はありますが、数時間遅れるだけなので、よほど最新の情報が求められていない限り問題ではないと思います。
さらに、こんなのはどうでしょう。
エラーが発生した検索サイトややたらと遅いサイトは、1回パスするのです。これにより、時間がかかるアクセスの回数が減り、ダウンロード処理時間の平均はさらに改善するのではないかと思います。
他にも、If-Modified-Sinceヘッダを導入するとか、gzipエンコーディングを利用するとか、試せそうな事は色々ありますね。
さっそく手を動かして色々改善してみようと思います。
2005年02月05日
次のチャンネル
現在、HeimdallrのPluginとしてキーワードチャンネル、トピックチャンネルの2つをリリースしています。
次に来るのは何か、という話ですが、次のチャンネルも、一応決まっています。
それはmixiチャンネルです。
mixiにアクセスしてマイミクシィ最新日記やコミュニティ最新書き込みを取得する機能を持つことになる予定です。
しかし、mixiチャンネルをHeimdallr 1.08に組み込むのは悩みどころです。
というのも、1.08までにキーワードチャンネルやトピックチャンネルの性能を向上させる必要があるので、mixiチャンネルまでやっていたら1.08安定版リリースがだいぶ遅れることが見込めるからです。
でもmixiチャンネルは、mixi使っている人からは魅力的かもしれません。私も使いたいのです。ということはやるべきでは・・・。しかしHeimdallrユーザにmixi使っている人っているのかな。もしほとんど居ないのであれば先に1.08安定版を出すべきでは・・・。さてはて・・・。という感じで悩み中です。
2005年02月04日
1月のカウンタートラックバック
1月中にHeimdallrを紹介して頂いた方々に対し、トラックバックを送ると共にお礼を込めてコメントなどを書かせて頂きたいと思います。
(1/12)RSSリーダー導入の巻
Windows9x対応って結構大変なんですよね。Windows9x対応を諦めると文字列をUnicodeだけで扱えるので内部の処理がずっとすっきりします。でもこの方のようにWindows9xに対応していてフリーだからという理由で使っている方を時々見かけますので、なかなか諦められません。
設定が面倒くさいというのには同意。ブラウザのブックマークに登録されているサイトを巡回して、RSS FeedをまとめてOPMLを生成するツールとかあったら便利なんじゃないかなぁ。
(1/16)理想の情報収集ツールとは
記事のPermlinkで「指定されたページまたはファイルは存在しません。」と言われるので1月分のまとめの方にリンクを張っておきます。
この記事で述べられている「思いっきり優秀な秘書」は、私が抱いているHeimdallrの最終形のイメージをずばり表しています。「自分にとって重要なニュースを出来る限り速く得ること」のために重要なプロセスは、クロール、リストアップ、ブラウズ、とあります。
Heimdallrとしては、最終的には、Channel Extension Pluginによる広範な情報ソースからのクロール、自動学習機能によるユーザの好みに合わせた最適なリストアップ、洗練されたマルチビューによる快適なブラウズ、を組み合わせることにより、「自分にとって重要なニュースを出来る限り速く得ること」ができればいいなぁ・・・と思っています。私の力でどこまで行けるか分かりませんけれど。
(1/17)読み捨て型RSSビューアHeimdalrの紹介
私の知る限り、Heimdallr Wikiを初めて紹介したのがこのサイトです。これで世に出ましたね。
(1/21)RSSリーダ「Heimdallr」
なかなか気合の入ったレビュー記事です。
RSSアイコンをHeimdallrにドラッグ&ドロップしたあと全て既読にする」というのはやっている人多いんですかね。私もいつもやってます。この動作がデフォルトにした方が良いかもしれませんね。でもこの動作をデフォルトにすると、ドラッグ&ドロップに成功したかどうか分からないんですよね・・・。
オンマウスポップアップが非常に鬱陶しいのです。
まず既読ボタンや日付表示、短縮名が消せないことが残念でした。1.08alpha2でポップアップウィンドウと記事のタイトルが重ならないように表示することができるようになりました。1.08alpha3ではさらに日付表示や短縮名を消すこともできるようになりました。これでだいぶ改善したのではないかと思います。
(1/21)RSS リーダー!
ブログへのコメントにも対応して欲しかったな。コメントもブログの一部なんだし。
この「コメント」というのがコメント書き込み機能を意味しているのか読み込み機能なのかがちょっと謎です。
書き込み機能の事だとすると、
Heimdallrは情報収集特化型なので発信系の機能は今後も搭載する予定はありません。
読み込み機能の事だとすると、RSS Feedにはコメント情報がないので対応できません。Blog提供側にコメントのRSSを出力してもらうようにするか、コメントチェッカーあたりと併用して下さい。ということになります。
(1/29)快適RSS生活のススメ「Heimdallr」
猫スキンよりも猫壁紙+透明スキンの方が猫ファン向けになるのかな・・・とふと考えさせられるスクリーンショットです。
Heimdallr利用中のスクリーンショットは度々見かけるのですが、使っているスキンは透明スキンがほとんどです。新しい透明スキンを追加してもいいかもしれませんね。
以上、今月は6件の紹介記事がありました。
今後もHeimdallrをよろしくお願い致します。
2005年02月03日
もぶろげっとβの使い道
電気通信大学情報工学科尾内研究室が画像情報統合型 Blog 検索エンジン「もぶろげっとβ」を公開しました。
検索結果がサムネイル画像付きで表示されるという特徴を持った検索エンジンです。これをHeimdallrのキーワードチャンネルで使うことを検討してます。
といっても、Heimdallrの今のGUIでは、サムネイル画像を取得できてもあまり有効に活用できないので、単なるRSSを出力する検索エンジンとして使うだけです。
そうなると、もぶろげっとが巡回しているのは今のところ、livedoor blog、goo blog、AOL Diary、Drecom Blog、2bee、ameba blogだけのようです。
他のRSS検索エンジンと比べて広い範囲を検索しているわけではないので、キーワードチャンネルがこの検索エンジンを使ってもユーザメリットがあるかどうかは良く分かりません。
うーん。何か生かす道は無いもんですかね。
2005年02月02日
Heimdalr 1.08alpha3リリース
Heimdallr 1.08alpha3をリリースします。
安定版ではありません。
安定版はHeimdallr 1.07です。
今回の主な変更はHeimdallrのビューを色々とカスタマイズできるようにしたことです。
詳しくは、「ビューのカスタマイズ」とビューカスタマイズその2を参照して下さい。
1.08alpha2→1.08alpha3の変更点詳細は以下の通りです。
- ビュー表示内容(短縮名、日付、タイトル)をカスタマイズできるようにしました。
- お気に入り優先度を変更できるようにしました。
- キーワードチャンネルとトピックチャンネルのサーバとの接続周りを若干変更しました。httpリクエストにUserAgentが付くようになり、また、長時間応答がない場合は切断するようにしました。
2005年02月01日
コメントが書き込めない不具合
コメント書き込みに対するシステムの応答が異様に遅いようでご迷惑をおかけしてます。これだけ遅いとちょっと書けたものではありませんね。
何でこんなことになっているのかちょっと調べてみました。
まず、このBlogで使用しているシステムを列挙してみます。
- (1) ネットワークデバイス(LANカードやらモデムやら色々)
- (2) OS Windows XP Professional SP2
- (3) Webサーバ アプリケーション Apache 2.0.52(Win32)
- (4) Perl ActivePerl v5.6.1
- (5) Blogツール Movable Type 3.122-ja
- (6) データベース MySQL 4.0.23
- (7) ディスクデバイス(IDE接続のHDDとIEEE1394接続のHDD)
色々調査した結果、以下のことが分かりました。
- (A) 外部からではなく、内部からWebサーバにFast Ethernetで繋いでもコメント書き込みは異様に遅いです。
- (B) ネットワーク共有(SMB)でWebサーバとファイルをやり取りする分には十分に高速です。
- (C) HDBenchでHDDの速度を見ても十分に高速です。
- (D) コメントを書き込むと「Perl Command Line Interpreter はエラーが発生し閉じられる必要がありました。」というエラーメッセージがWebサーバの画面に表示されます(なんじゃそりゃ!)。
- (E) Webサーバのエラーログには以下のメッセージが残っています
DBD::mysql::db disconnect failed: handle 2 is owned by thread 15af3a8 not current thread 430e8ec (handles can't be shared between threads and your driver may need a CLONE method added) at XXX/mt/lib/MT/ObjectDriver/DBI.pm line 327. - (F) Webサーバのエラーログには以下のメッセージが残ることもあります。
(70007)The timeout specified has expired: ap_content_length_filter: apr_bucket_read() failed - (G) MySQLを使う前にはBerkeley DBを使っていました。MySQLに変えたことにより、Movable Typeのコメント書き込み以外の機能(エントリ編集やサイトの再構築)はだいぶ快適になりました。
- (H) Berkeley DBを使っていたころは、(D)(E)(F)のエラーは出ませんでした。
さて考察してみます。
まず、(A)(B)より(1)に問題がある可能性は低そうです。
また、(B)(C)より、(2)(7)に問題がある可能性も低そうです。
(D)は怪しいですね。怪しすぎます。これだけ見ると原因は(4)ではないかという気がします。
(E)より(5)も怪しくなってきました。
(F)はちょっと意味不明。(D)か(E)の余波を受けている気がします。
(G)より(6)は問題ないのではないかと思います。
でも(H)により(6)もちょっと怪しくなってきました。
しかし(6)は実績のあるアプリケーションなので、(5)が(6)を使っている部分を先に疑った方が良さそうです。
(3)は話に出てきてませんが、これも実績のあるアプリケーションなのでとりあえず置いておきます。
というわけで残った候補は(4)(5)です。
ここから先のカラクリは良く分かりませんが、(5)が(4)が抱えているバグを掘り出してしまってこんな現象になっている、というあたりでしょうかね。コメント書き込み以外はうまく動いているわけですから、(5)がなんらかの対応を行うことにより本問題も回避できそうな気がします。
とりあえずSix ApartさんからリリースされたMovable Type3.15の日本語版を入れてみて、問題が解決されていなければエラーメッセージを揃えてサポートに突撃、ということにしようと思います。